Designing privacy friendly analytics

It was only two weeks ago that I wrote
but I've whittled the amount of javascript on the site right down, and don't really relish the thought of increasing it. Nor do I particularly like the idea of implementing probes that can track user movements across my sites, when all I currently need is aggregate data.
Unfortunately, that set my brain wandering off thinking about what scalable privacy friendly analytics might look like - which inevitably led to prototyping.
Fundamentals
The system is supposed to be privacy friendly, so there are some fundamental rules I wanted to abide by
- Actions and time are the primary focus, not the user - we don't need to record user identifiers
- The system should be lightweight and collect only that which is needed
- There should be no ability to track a user cross-site (even if the analytics is used on multiple sites)
- The default behaviour should make it all but impossible to track user movements within a site
The aim being to strike a balance where we can collect the data required to maintain/improve a site, with as little impact on the user's privacy as possible.
Whilst I trust me, there's no reason users should have to, and we should assume that at some point, someone less trustworthy will find a way to access the stored data: the less identifying data available, the less use it is to them.
Information collected
The system collects the following information from a user's browser
- Domain
- Page
- Referrer (if available)
- Platform (e.g.
Linux x86) - Timezone (offset from GMT)
- Page load time
- Number of pages viewed this session
Referrer is collected because it's useful to see where traffic is being sourced from - especially if there's a sudden drop-off (plus, it's interesting to see where I'm being linked to from).
Platform and Timezone are useful for planning and scaling purposes, and page load times are obviously useful for evaluating performance of the site.
The number of pages viewed in a session allows evaluation of the bounce rate, but requires storage of state in the user's browser - the sessionStorage object is used to store the counter for this, so state won't be tracked between browsing sessions (or even browser tabs).
Most importantly, none of this information is tied to a user's IP, and by default no session identifiers are used at all (more on that in a bit).
Implementation
The system is implemented in the form of three components
- Javascript agent
- LUA translater
- Storage layer
The agent is pretty simple - information collection is performed by the following function
function gatherInfo(){
var tz = new Date().getTimezoneOffset();
var referrer_domain = '';
var referrer = document.referrer;
if (referrer.startsWith(document.location.protocol + "//" + document.location.hostname)){
// In-site navigation, blank the referrer - we're not looking to stalk users around the site
referrer = '';
}
if (referrer.length > 8){
referrer_domain = new URL(document.referrer).hostname;
}
return {
domain : window.location.hostname,
page: window.location.pathname,
viewed_pages: incrementPageViews(),
referrer: referrer,
referrer_domain: referrer_domain,
platform: navigator.platform,
timezone: tz,
sess_id: getSessionId(),
responseTime: window.performance.timing.domContentLoadedEventStart - window.performance.timing.navigationStart
}
}
The complexity around referrer is simply to ensure that we don't send referrer if the user is navigating within the site (Rule 4).
The LUA translater then takes this JSON, does some validation (scrub junk entries etc) and translates it into Line Protocol ready for writing into InfluxDB.
function build_lp(ngx, measurement)
local get, post, files = require "resty.reqargs"()
-- post is a table containing the decoded JSON
-- Run safety checks
validate_write(post)
-- Skip domains specifies domains that we do nothing for - just return a 401
skip_domains = strSplit(",", ngx.var.skip_domains)
if table_contains(skip_domains, post['domain']) then
ngx.exit(401)
end
local ts = ngx.now() * 1000
allowed_domains = strSplit(",", ngx.var.permitted_domains)
if not table_contains(allowed_domains, post['domain']) then
-- Content being served from somewhere unauthorised
-- websites/privacy-sensitive-analytics#3
return build_unauth_lp(post, ts, measurement)
end
-- TODO: do we want to include the first bit of the path as a tag?
-- perhaps the first 2 directories deep?
sec1 = {
measurement,
"domain=" .. string.lower(post['domain']),
'type="pageview"',
'page="' .. post['page'] .. '"'
}
if tableHasKey(post, "sess_id") and post["sess_id"] ~= "none" then
table.insert(sec1, 'sess_id="' .. post["sess_id"] .. '"')
end
fields = {
"timezone=" .. post['timezone'] .. "i",
'referrer="' .. post['referrer'] .. '"',
'referrer_domain="' .. string.lower(post['referrer_domain']) .. '"',
'platform="' .. string.lower(post['platform']) .. '"',
"response_time=" .. post['responseTime'] .. "i",
"viewed_pages=" .. post['viewed_pages'] .. "i",
}
-- Put them together
join_t = {
table.concat(sec1, ","),
table.concat(fields, ","),
ts
}
-- Final concat
return table.concat(join_t, " ")
end
So, we return some LP that looks a bit like this
pf_analytics_test,domain=www.bentasker.co.uk,type="pageview",page="/posts/blog/the-internet/attempting-to-control-youtube-access-on-android.html" timezone=0i,referrer="https://www.google.co.uk/",referrer_domain="www.google.co.uk",platform="linux x86_64",response_time=229i,viewed_pages=1i 1640089140878
I opted to have referrer, platform and timezone as fields to keep cardinality down - it's an unusual approach, but having a mischievous mind myself, I tend to assume that at some point, someone's going to come along and try fuzzing the system.
The data ultimately gets written into InfluxDB, and can be reported on from there.
Scalability
I currently have limited need to scale this up, but wanted to make sure that some scaling was possible. There are a couple of aspects to this - infra/hardware and the data itself.
Hardware
It's plausible that, at some point, the layer running the LUA translator may need scaling - there are a finite number of workers, and each POST in will tie one up whilst the processing and upstream write complete.
Having each node write (1 point at a time) directly to InfluxDB is potentially going to turn into a headache if scaled too far - and even without that, you have to consider connectivity between your LUA node and InfluxDB (high latency means each POST takes longer to complete).
It's a fairly trivial problem to address though: rather than running InfluxDB on that node, you run Telegraf with the InfluxDB listener active. That's as simple as adding
[[inputs.influxdb_listener]]
service_address = "127.0.0.1:8086"
to the Telegraf config.
The LUA layer will then write into Telegraf, which'll write onward to InfluxDB in batches. So, LUA gets fast writes (reducing contention at that layer) and you minimise the risk of lost writes.
Data
This is a little harder to address, and requires a little bit of compromise.
To understand the issue, if we take the LP from above, the series (comprised of measurement, tagset and field names) is
pf_analytics_test,domain=www.bentasker.co.uk,type="pageview",page="/posts/blog/the-internet/attempting-to-control-youtube-access-on-android.html" timezone,referrer,referrer_domain,platform,response_time,viewed_pages
The timestamp uses millisecond precision: 1640089140878
The problem is, if another request with the same series were to be logged in the same millisecond, the 2nd record would overwrite the 1st.
On a low traffic site, there's a low risk of that happening - 1ms difference means the issue doesn't occur, but a busy site has a higher chance of it occuring.
This is, to some extent, exacerbated by my decision to set referrer etc as fields rather than tags - the additional cardinality would further reduce the likelihood of this occurring (though not entirely eliminate it).
In a traditional analytics system, this isn't much of an issue, because you've got a unique differentiator: the user's IP. But the whole point of this system is that we're not supposed to be able to tie activity back to a given user.
As a quick fix, I decided to add client side generation of a random session identifier
function getSessionId(){
// Only if enabled
if (!window.analytics_gen_psuedoid){
return "none";
}
var k = window.location.hostname + "_sess-id";
var i = sessionStorage.getItem(k);
if (!i){
i = createUUID();
sessionStorage.setItem(k,i);
}
return i;
}
function createUUID() {
// Create a short UUID
return 'xxxx-xxxx'.replace(/[xy]/g, function(c) {
var r = Math.random() * 16 | 0, v = c == 'x' ? r : (r & 0x3 | 0x8);
return v.toString(16);
});
}
This generates an 8 character session identifier (e.g. bc05-0d99). sessionStorage is used so that the UUID doesn't persist between browsing sessions, or even get shared between browser tabs. When present, we use it as a tag, addressing the issue of overlapping writes.
When enabled (it's off by default), this UUID provides some uniqueness to help prevent collisions. However, it also violates principal 4: the UUID could be used to track a user's movement within the site during that browsing session, which is not ideal.
The UUID is stripped when downsampling from recent to historic storage, which mitigates the impact of this change a little.
Whilst I could have generated a unique ID for each page, the result would be massive cardinality (a series per page view, in fact), so this seemed better. Technically you could, perhaps, have the client generate a nonce and hash that together with the user's IP (letting the agent decide when to rotate the nonce), but the complexity that that adds makes things less transparent to the user (although, now that I think about it, I may allow the agent to randomise rotation of the session identifier).
Reporting
With the data in InfluxDB, reporting is pretty straightforward - just a case of making a couple of dashboards
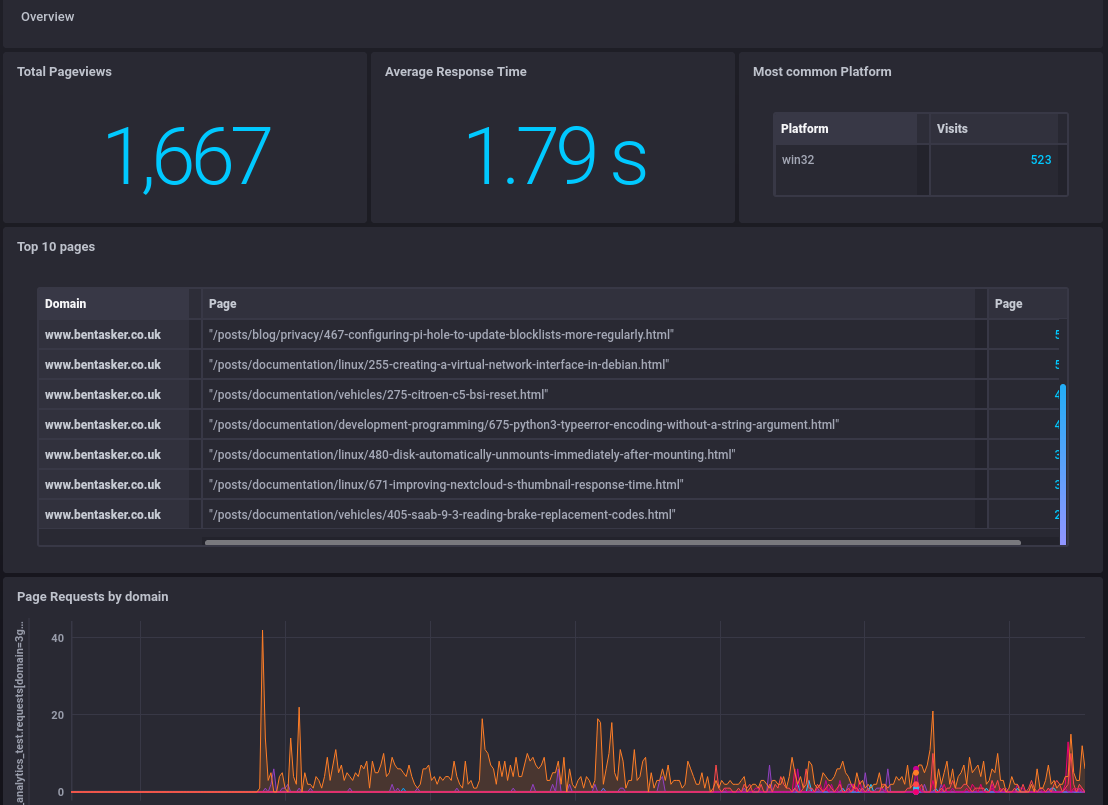
At a glance, I've got the stats that mattter - how much traffic's coming in, the average page load time (skewed up by the .onions if you're wondering), which pages are doing well and what request rate each domain is seeing.
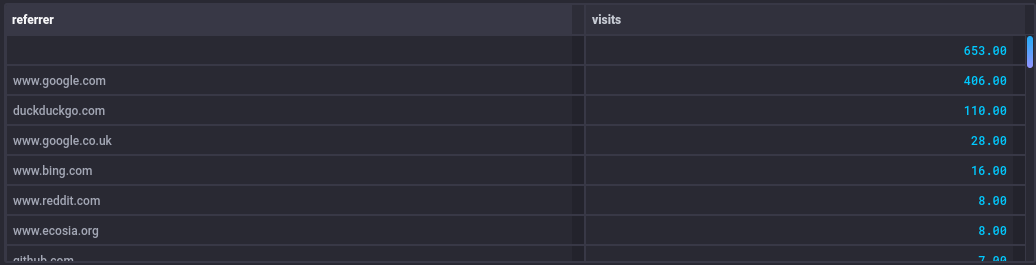
I can also pivot out referrer, platform and timezone information with some Flux like the following:
from(bucket: "telegraf/autogen")
|> range(start: v.timeRangeStart)
|> filter(fn: (r) => r._measurement == "pf_analytics_test")
|> filter(fn: (r) => r.domain == v.domain)
|> filter(fn: (r) => r._field == "referrer_domain")
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> group(columns: ["referrer_domain"])
|> count(column: "page")
|> map(fn: (r) => ({ visits: r.page, referrer: r.referrer_domain}))
|> group()
|> sort(columns: ["visits"], desc: true)
Giving
Long Term Storage
The information above is only retained for about a week - I don't need that kind of granularity longer term.
For longer term use, the information is downsampled into 15 minute aggregates - at this point, the optional session identifiers are stripped (if they were even enabled in the first place).
The referring domain field is reduced in granularity and turned into a tag - as a short example, the following Flux will collapse all domains starting with www.google down to just google.
import "strings"
from(bucket: "telegraf/autogen")
|> range(start: ''' + START + ''')
|> filter(fn: (r) => r._measurement == "pf_analytics_test")
|> filter(fn: (r) => r._field == "referrer_domain")
|> filter(fn: (r) => r._value != "")
|> map(fn: (r) => ({ r with _field:
if (strings.hasPrefix(v: r._value, prefix: "www.google")) then "google"
else r._value}))
|> drop(columns: ["sess_id"])
|> aggregateWindow(every: 15m, fn: count)
|> map(fn: (r) => ({r with referringdomain: r._field, _field: "viewcount"}))
The response is processed further in Python (The plan is to have it email a periodic report) and then written back in (otherwise I'd have used to()).
Response time gets broken down into mean, min and max
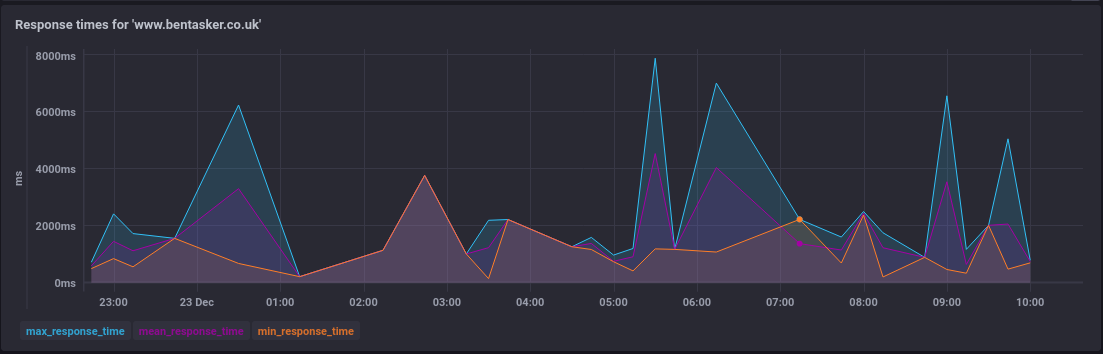
Along with 95th percentile - courtesy of the quantile() function.
I've not actually implemented any processing on the stat detailing how many pages a visitor has viewed - it's not proven to be as useful/interesting as I assumed, so I've removed it from the agent.
With the long term data now in a more normalised format, if I later decide that further downsampling is necessary, I can easily do so with a continous query or task.
Further Improvements
There are some additional improvements I've added since I started writing up this post
- In order to further dissassociate users, analytics writes come in via CDN - that way the user's IP is never available to my equipment.
- The session ID rotates semi-randomly (with a
1:10of any rotation occurring) - If you're viewing my content via a
.onionthen the analytics writes will also go via a.onion, keeping everything in-network and removing my CDN provider from the equation
In future, I'd like to collect some basic User-agent stats, but there's some caution needed here as it can contribute toward user specific fingerprinting (my current line of thinking is to have the agent normalise before submitting).
Conclusion
There are, obviously, some sacrifices compared to a traditional analytics system - I can't, for example, track whether a user is a repeat visitor. But, that's very much by design: I'm collecting the stats required to monitor and improve delivery of my content, whilst keeping that information entirely disaccociated from users themselves.
There's no good reason to record a user's IP, in perpetuity, to track pageviews. There are some arguments for tracking subnet/AS along with response times, but I'm not currently responsible for the delivery network, so there's little need for me to capture that information. I can however, identify when users in a given timezone are being underserved.
What I've got, then, is a high level overview of when and where my sites are accessed, and how long it takes to reach DomReady. Being JS dependant, the stats will exclude (most) bots, so the stats collected will generally represent real users. Some real users will block javascript, and so will also be excluded - whilst it's possible to collect stats on this (by using noscript and the like), it's doesn't feel right to do so.
I mentioned earlier that it's interesting to see where traffic is coming from, and one thing that I sometimes find myself doing, is looking at pages that link to me. The reports above only show domain and don't allow me to drill down, however, I can quite easily look up the full referrer URL with the following Flux
import "strings"
// Set this to the referrer domain to search for
domain = "github.com"
from(bucket: "telegraf/autogen")
|> range(start: -7d)
|> filter(fn: (r) => r._measurement == "pf_analytics_test")
|> filter(fn: (r) => r._field == "referrer")
|> filter(fn: (r) => strings.containsStr(v: r._value, substr: domain))
|> group()
|> drop(columns: ["_field", "_measurement", "host"])
There will, undoubtedly, over time, be some evolution in the stats I collect (I'd like to come up with a good time-on-page collector) and the way I process them, but this initial implementation has shown that it's perfectly possible to do so in a way that doesn't tie visits to the vistors themselves.
There are some additional stats I'd like to collate in future, but haven't yet thought through how best to go about it. At first glance, the most privacy friendly approach is to normalise/anonymise on the client side, but that increases complexity of the agent - ideally I'd like it to be relatively simple so that curious users can quite trivially audit it.
I've always tried to go over and above when it comes to privacy and transparency on my site, there's a fine balance to maintain between necessary operational data and user privacy, and hopefully this will allow me to better strike that balance.
You can view the full agent here