Tightening Controls over Public Activity Feeds on Mastodon

At times, the last couple of weeks have been fairly busy for privacy on Mastodon, with two different but interrelated concerns rearing their heads.
The first was Boyter's Mastinator.com, a federated solution which allowed the following of arbitrary accounts, potentially enabling others to circumvent blocks as well as being problematic for the privacy of "Follower Only" posts.
The second was Matt Cloy's #fediblock post about a non-federated full-text search engine:
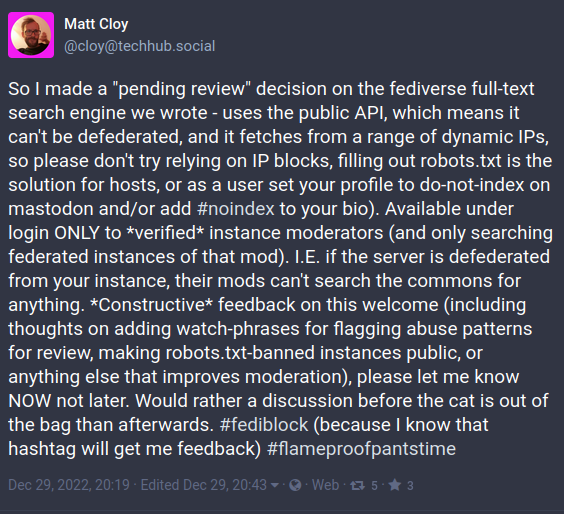
Inevitably, this provoked a strong reaction: full-text search is a hot topic, having historically been used to help target harrassment campaigns, something personally experienced by many of those objecting.
For avoidance of doubt, the solution was never publicly available (Matt has confirmed it now never will be and was only ever used for testing).
@cloy's implementation worked by placing requests to Mastodon's public API endpoints and so could not simply be defederated in the way that an ActivityPub implementation like Mastinator might be addressed.
As noted in the opening #fediblock message, the indexer's requests originate from various (changeable) IPs, so relying on simple IP blocklists would be ineffective (and even if that were not the case, would still serve only to block this particular instance). Although easily misinterpreted as a deliberate circumvention attempt, this kind of IP cycling is extremely common where public clouds are used to run workloads (whether on something like an AWS EC2 instance, or a container in AWS Fargate), which probably goes some way to explain the suggestion of using a common signal: robots.txt.
This is clearly an example of a different threat model to that of Mastinator: it involves an external entity requesting and indexing the responses of public API endpoints, whilst potentially taking measures to circumvent targeted blocking attempts (even if that wasn't occurring here).
Of the two threats, it's implementations like @cloy's that I intended to focus on in this post.
There's no denying that the way in which the issue was raised was extremely counter-productive, but there is some truth in Matt's later arguments that others are already quietly doing this and that Mastodon perhaps doesn't do enough to restrict access to these feeds.
Ultimately, Matt's account at techhub.social was suspended and then deleted: an unfortunate (if predictable) result of perceived rage-baiting.
The whole affair prompted me to take a deeper look at exactly how such an implementation might work, in order to see what can be done to try and prevent (or at least mitigate) similar attempts in a way that delivers a better success rate than that achievable by reactively blocking IPs.
During the process, I reviewed my own instance's logs and stumbled across a handful of crawlers that are (or were) periodically scraping my instance's public APIs for whatever ends.
In this post, I'll provide details of those crawlers (so that other instance admims can proactively block any that they weren't already aware of), the defensive tools that Mastodon provides and a method for covering the gaps that Mastodon unfortunately leaves open.
Contents
- Individual User Protections
- Mastodon
- An Observed Scraper
- Requiring Authentication For Trends
- Active Checks
- Additional Protection Mechanisms
- Larger Instance Admin Considerations
- Cloudflare Worker Example
- Observed Scraper IPs
- Conclusion
Individual User Protections
This post is quite heavily focused on the instance level, and as such isn't really targeted at non-admin users, who generally lack the privileges to change anything detailed here.
However, there are things that an individual user can do to help (slightly) reduce the likelihood of their accounts being indexed/profiled
- Opt Out of Search Engine Indexing
- Consider disabling display of your social graph
- Consider whether you want to require approval of Follow Requests (
Preferences->Profile->Require follow requests)
They may also want to add #nobots to their profile as it's a common signal (if somewhat likely to be ignored by the sort of operations that we should be most concerned about).
Mastodon
Most of this section will probably be familiar to instance admins, but it's worth laying out a high level overview of what Mastodon provides, so that we know what we're working with.
Public API Endpoints
Mastodon exposes a number of public API endpoints, some of which you probably want to remain publicly available, for example
/api/v1/custom_emojis/api/v2/instance
However, there are also endpoints which detail activity on the instance
- Trending tags:
/api/v1/trends/tags - Trending toots:
/api/v1/trends/statuses - Local feed:
/api/v1/timelines/public?local=true&only_media=false - Federated Feed:
/api/v1/timelines/public?remote=false&allow_local_only=false&only_media=false
These are called to populate the tabs on the instance's default page
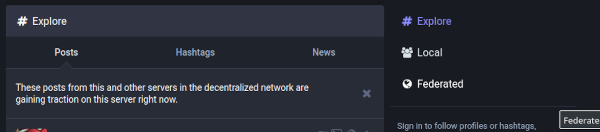
Requests are also made to them when logged in users view trends/hashtags etc, whether from the Web UI or a mobile app.
Even without the existence of indexers, these feeds are potentially problematic, and I've written previously about how the existence of these public feeds can reveal unwanted information, particularly on smaller instances.
Mastodon's Controls
Mastodon does include a configuration option to shield some of this information from public view.
Within the server preferences is the option (Preferences -> Administration -> Server Settings -> Discovery -> Allow unauthenticated access to public timelines)

However, this only disables unauthenticated viewing of Local and Federated.
Crawlers will still be able to use the trends/ endpoints to access information about trending content on your instance. In practice, this means that the Mastodon instance is doing half the scrapers work for them by sorting and exposing only the most popular content (sorting the wheat from the chaff, as it were).
Mastodon 4.x introduced a new configuration variable: DISALLOW_UNAUTHENTICATED_API_ACCESS (thanks to @jerry for pointing me towards it).
When enabled, the instance will require all API calls to be authenticated.
Although this prevents unauthenticated access to the trends endpoints it also means that links to profiles and posts will not work for unauthenticated users.
Whilst the setting obviously provides a much higher level of protection, it comes at the cost of some of the usual workflows:
- Users from other instances will be unable to view anything after selecting
Open Original Pagein the Web UI/App for one of your users (so they won't be able to see interactions that their instance doesn't display). - Admins on other servers won't be able to look at the overall behaviour of a user on your server whilst investigating an abuse report, or worse a
#fediblockreport (I've a horrible feeling that some of the less pleasant instances might start enabling this setting for exactly that reason).
As with any new functionality, there have also been reports of issues with its initial implementation.
Still, it is an option for admins who want the strongest level of protection and are willing to tolerate the drawbacks.
An Observed Scraper
When first looking into this, I had already unticked Allow unauthenticated access to public timelines, preventing unauthenticated access to the Local and Federated feeds and so had assumed that I wouldn't find much in terms of successful scraping/crawling attempts in my logs.
I was wrong... I found log entries showing a crawler periodically pulling information on trends from my instance
129.153.55.48 - - [02/Jan/2023:06:59:13 +0000] "GET /api/v1/trends/statuses?limit=40&offset=0 HTTP/1.1" 200 3342 "-" "axios/1.2.1" "-" "mastodon.bentasker.co.uk" CACHE_- 0.129 mikasa -
129.153.55.48 - - [02/Jan/2023:07:18:30 +0000] "GET /api/v1/trends/statuses?limit=40&offset=0 HTTP/1.1" 200 2259 "-" "axios/1.2.1" "-" "mastodon.bentasker.co.uk" CACHE_- 0.082 mikasa -
The crawler running at 129.153.55.48 hits my instance every 20 minutes (at rough 8 minute offsets) and fetches the trending toot list (the user-agent implies it's built using Axios which is a NodeJS HTTP Request library).
There are occasional requests to fetch a toot (presumably because either my, or someone else's trending list) included it.
129.153.55.48 - - [28/Dec/2022:00:58:16 +0000] "GET /api/v1/trends/statuses?limit=40&offset=40 HTTP/1.1" 200 33 "-" "axios/1.2.1" "-" "mastodon.bentasker.co.uk" CACHE_- 0.050 mikasa - "-" "-" "-"
129.153.55.48 - - [28/Dec/2022:00:58:16 +0000] "GET /api/v1/trends/statuses?limit=40&offset=0 HTTP/1.1" 200 7855 "-" "axios/1.2.1" "-" "mastodon.bentasker.co.uk" CACHE_- 0.143 mikasa - "-" "-" "-"
129.153.55.48 - - [28/Dec/2022:01:00:26 +0000] "GET /api/v1/statuses/109585997399946330 HTTP/1.1" 200 1421 "-" "axios/1.2.1""-" "mastodon.bentasker.co.uk" CACHE_- 0.098 mikasa - "-" "-" "-"
The delay between requests might be a sign that the toot was referred to in a trending list on another instance, but may also just be a sign that the crawler adds toots to a queue rather than fetching them immediately.
As is my wont, I've done some osint on the system behind this IP. Sharing that is not the purpose of this post, however I have confirmed that
- it's not a residential IP, so the information above shouldn't help directly identify anybody
- it does not appear to be related to Matt Cloy's proposed crawler (the portal for which, incidentally, is no longer online)
I've spoken privately with a number of instance admins and have confirmed that this crawler shows up in the logs of quite a range of instances.
The Crawler's Purpose
There are a wide range of organisations interested in social media activity, most of which are pursuing one commercial model or another (I don't doubt though, that there are some intelligence agenices mixed in).
Amongst those will be organisations who specialise in brand reputation monitoring, as well as those who create social media walls for display in hotels, service stations and news feeds.
The observed behaviour of the crawler certainly fits the behavioural pattern you'd expect for something like a social media wall:
- Hit known instances and grab information on trending toots/tags
- Retrieve those toots (or a selection of)
- Compile results and display
Of course, as others pointed out during the #fediblock discussion, this necessarily entails republishing content without the author's permission. This is not corporate social media, there is no perpetual worldwide license authorising re-use of user's toots and doing so is often considered unwelcome.
Crawling trends rather than Local or Federated could also, theoretically, be used to address data reduction issues whilst indexing the fediverse. Using trending as a signal allows an indexer to only use storage and compute resources indexing higher profile content (whether that results in a useful search experience depends on the intended use of the index).
I'm inclined to think that this particular crawler probably best fits the media wall use-case, especially given the regularity with which it checks back against even my (tiny) Mastodon instance.
IP Blocks
The obvious first impulse, is to block the crawler's IP: it's a known bad actor and there's no point wasting time sending it a SYN-ACK, much less handling SSL handshakes and accepting a request.
However, blocking by IP is an incredibly limited approach and has long been unable to give any real assurance: circumventing IP blocks has never been particularly difficult and yet still manages to be far easier and cheaper than it's ever been.
The increased existence of CGNAT on ISP networks also means that there's a non-zero probability that any given IP block might accidentally block more than expected - potentially leading to legitimate users accidentally being denied service.
Even without those (significant) drawbacks, manually curated IP blocklists also don't do very much to protect instances against the next bad actor to pop up using the same technique - it's an entirely reactive defence, because the behaviour needs to occur for you to become aware and block.
So, whilst IP Blocking is an easy way to achieve short-term relief, where possible, it should always be followed up with behavioural rules.
Requiring Authentication For Trends
Mastodon doesn't currently provide a means to require authentication for the trends feed, other than by enabling DISALLOW_UNAUTHENTICATED_API_ACCESS.
Whilst it's more than possible to fork Mastodon and implement additional protections, that approach isn't particular appetising: it'd mean committing to maintaining the fork everytime a new Mastodon instance was released.
Instead, I wanted to be able to place protections in front of Mastodon - on a CDN, a Web Application Firewall (WAF) or even just a reverse proxy - so that future software updates aren't delayed by the need to merge changes back into a fork.
Browser Behaviour
Using a browser's Developer Tools we can see that the way that Mastodon's UI forms it's requests for public endpoints differs depending on whether the user is authenticated or not.
For ease of comparison, the Copy as cURL option has been used to extract the requests:
Unauthenticated
curl 'https://mastodon.bentasker.co.uk/api/v1/trends/statuses' \
-H 'User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:108.0) Gecko/20100101 Firefox/108.0' \
-H 'Accept: application/json, text/plain, */*' \
-H 'Accept-Language: en-GB,en;q=0.5' \
-H 'Accept-Encoding: gzip, deflate, br' \
-H 'Referer: https://mastodon.bentasker.co.uk/' \
-H 'X-CSRF-Token: <a token>' \
-H 'DNT: 1' \
-H 'Connection: keep-alive' \
-H 'Cookie: _mastodon_session=<a session id>' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Pragma: no-cache' \
-H 'Cache-Control: no-cache' \
-H 'TE: trailers'
Authenticated
curl 'https://mastodon.bentasker.co.uk/api/v1/trends/statuses' \
-H 'User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:108.0) Gecko/20100101 Firefox/108.0' \
-H 'Accept: application/json, text/plain, */*' \
-H 'Accept-Language: en-GB,en;q=0.5' \
-H 'Accept-Encoding: gzip, deflate, br' \
-H 'Referer: https://mastodon.bentasker.co.uk/' \
-H 'X-CSRF-Token: <a token>' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Authorization: Bearer <an auth token>' \
-H 'Connection: keep-alive' \
-H 'Cookie: _session_id=<another session id>; _mastodon_session=<a session id>' \
-H 'Pragma: no-cache' \
-H 'Cache-Control: no-cache' \
-H 'TE: trailers'
Despite the API not actually requiring authentication, the Authenticated request provides two extra items
- There's an extra cookie
session_id - An API auth token is provided in the
Authorizationheader
This may be a happy accident, or it might be that the result varies based on the user's ID. For our purposes, it doesn't really matter which, the important thing is that it means there's a way to differentiate between an authenticated and an unauthenticated request at the HTTP level.
Designing Auth Rules
The availability of these request specifics means that we can design some criteria to use so that a WAF rule can decide whether to permit a request or not:
In psuedo-code we could write a rule that looks like
if req.path == "/api/v1/trends/statuses":
if "authorization" not in req.headers:
deny()
if "_session_id" not in req.cookies:
deny()
allow()
The request items are also present in authenticated calls to the Local and Federated views, so the same ruleset can potentially be used to add an additional layer of protection to those too.
A ruleset like this should be absolutely trivial to configure in a variety of WAF products.
Testing for evasion
Before embarking on that path though, I wanted to check how easily this simple ruleset could be evaded.
Unfortunately there's a problem: testing for existence isn't enough.
If an invalid authentication token (or session id) is included in the request, the WAF will detects it's presence and proxy the request through to Mastodon. Unfortunately, rather than rejecting the request, Mastodon ignores the invalid items and returns the requested feed (most likely, on those endpoints, it's not actually checking the auth token's presence or validity at all).
This means that our simple ruleset can be circumvented by simply including nonsense
curl 'https://mastodon.bentasker.co.uk/api/v1/trends/statuses' \
-H 'User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:108.0) Gecko/20100101 Firefox/108.0' \
-H 'Accept: application/json, text/plain, */*' \
-H 'Accept-Language: en-GB,en;q=0.5' \
-H 'Referer: https://mastodon.bentasker.co.uk/' \
-H 'X-CSRF-Token: <a token>' \
-H 'Sec-Fetch-Dest: empty' \
-H 'Sec-Fetch-Mode: cors' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Authorization: Bearer na-na-na-na-na-notarealtoken' \
-H 'Connection: keep-alive' \
-H 'Cookie: _session_id=geeIbetYouWishThisWereRealMrAdmin; _mastodon_session=<a session id>' \
-H 'Pragma: no-cache' \
-H 'Cache-Control: no-cache' \
-H 'TE: trailers'
This doesn't completely invalidate the ruleset: much like moving SSH from port 22, despite being easily defeated, it raises the bar a little, excluding some of the lower hanging fruit.
Of course, the more widely adopted the ruleset, the more likely that bot authors will include this simple circumvention.
Active Checks
Whilst it's dissapointing the Mastodon doesn't reject invalid tokens, there is still a path forwards: Rather than simply requiring the presence of a token, we should instead require the presence of a valid token.
Tokens are minted per-session rather than per-request, so our WAF can check validity by using it to make an upstream request to an authenticated API endpoint before placing the real request.
This would mean request flows something like the following
Valid user:
-------------------------
| Mastodon |
-------------------------
^ 3.| ^ 5. |
| | | |
GET | GET |
/test | (token) |
(token) | | |
| 200 | 200
| | | |
2.| V 4.| V
-------------------------
| WAF |
-------------------------
^ 6.|
| |
GET 200
(token) |
| |
1.| V
-------------------------
| Client |
-------------------------
-------------------------------
Bot:
-------------------------
| Mastodon |
-------------------------
-------------------------
| WAF |
-------------------------
^ 2.|
| |
GET GTFO
| |
1.| v
-------------------------
| Bot |
-------------------------
Testing the token also means that we no longer need to test for the presence of a _session_id cookie: having a valid token is sufficient to prove access to the instance (Mastodon's API accepts it, so we should too).
However, this approach is not without it's dawbacks:
Using an active check makes implementation a little harder, because rather than a simple rules-based WAF, we now need something capable of running dynamic code against requests.
There is a small additional risk inherent in the design: for each (valid) downstream request to the protected API endpoint, the WAF would make two requests (the token-test probe and the real request), providing a small amplification vector to someone wanting to try and drive up origin load.
There are, however, mitigations which can be designed in
- Endpoints like
/api/v1/trends/statusesshould be fairly cacheable, so the second response could be served from a cache, preventing it from contributing load to the origin - A cache could also be used for the probe results so that the same token is not repeatedly re-checked
I prefer the second mitigation, because it's not so subject to future changes in Mastodon's behaviour.
In addition to being mitigable, the range of users able to exploit this should be relatively small: By definition, to achieve amplification, a valid token would need to be provided (otherwise the second upstream request will never be made), limiting the subset of possible adversaries to existing user accounts, rather than internet randomers. So any potential attacker would need to have (or compromise) an account on the targeted instance.
LUA Implementation
I've historically built quite a lot using OpenResty. Not only can it run LUA, but it can also usually act as a drop in replacement for a vanilla NGINX build, meaning that an implementation built with it would be potentially viable for any instance admins who currently front Mastodon with Nginx.
I've previously done some work on (and written about) analysing the results of a WAF ruleset written in LUA, which brings with it a lazy bonus: I wouldn't need to design and build a reporting solution, because I already have one.
Given the arguments in it's favour, I decided to build the first implementation using LUA and (based on little more than a finger in the air) to have it call the Suggestions API endpoint in order to verify that the token provided in the request from downstream is valid.
Doing things slightly backwards, to deploy, I did the following
mkdir -p /etc/nginx/domains.d/LUA/resty
cd /etc/nginx/domains.d/LUA/resty
# Get Deps
wget https://github.com/ledgetech/lua-resty-http/raw/master/lib/resty/http.lua \
https://github.com/ledgetech/lua-resty-http/raw/master/lib/resty/http_headers.lua \
https://github.com/ledgetech/lua-resty-http/raw/master/lib/resty/http_connect.lua
The following LUA was then written to implement the ruleset, saved to disk as /etc/nginx/domains.d/LUA/enforce_mastodon.lua
--
-- enforce_mastodon.lua
--
-- Nginx config requirements
--
-- Following vars must be defined in Nginx config
--
-- $origin Origin IP domain
-- $origin_port Origin Port
-- $origin_host_header the host header to pass through
-- $origin_do_ssl set to "no" to disable upstream SSL
--
-- It also requires that a shared dict called mastowaf_cache have
-- been defined
-- We rely on https://github.com/ledgetech/lua-resty-http
-- to make the upstream request
local http = require("resty.http")
function place_api_request(ngx, auth_header)
-- Place a request to the origin using the /api/v2/suggestions endpoint
--
-- This path requires authentication, so allows us to verify that a provided
-- authentication token is valid
-- Initiate the HTTP connector
local httpc = http.new()
ok,err = httpc:connect(ngx.var.origin,ngx.var.origin_port)
if not ok
then
ngx.log(ngx.ERR,"Connection Failed")
return false
end
if ngx.var.origin_do_ssl ~= "no" then
session, err = httpc:ssl_handshake(False, server, false)
if err ~= nil then
ngx.log(ngx.ERR,"SSL Handshake Failed")
return false
end
end
headers = {
["user-agent"] = "WAF Probe",
host = ngx.var.origin_host_header,
Authorization = auth_header
}
local res, err = httpc:request {
path = "/api/v2/suggestions",
method = 'GET',
headers = headers
}
-- We're done with the connection, send to keepalive pool
httpc:set_keepalive()
-- Check the connection worked
if not res then
ngx.log(ngx.ERR,"Upstream Request Failed")
return false
end
-- Check the status
if res.status == 200
then
-- Authorised!
return true
end
ngx.log(ngx.ERR, res.status)
return false
end
function validateRequest(ngx)
-- The main work horse
--
-- Take the Authorization from the request
-- Deny if there is none
-- Check cache for that token and return the result
-- If needed, place upstream request to check that the token is valid
-- Return true to allow the request, false to deny it
local auth_header = ngx.var.http_authorization
-- Is the header empty/absent?
if auth_header == nil then
ngx.log(ngx.ERR,"No Auth Header")
ngx.header["X-Fail"] = "mastoapi-no-auth"
return false
end
-- Check the cache
local cache = ngx.shared.mastowaf_cache
local cachekey = "auth-" .. auth_header
local e = cache:get(cachekey)
-- See if we hit the cache
if e ~= nil then
if e == "true" then
return true
end
ngx.header["X-Fail"] = "mastoapi-cached-deny"
return false
end
-- We got a value, do a test request with it
local api_req = place_api_request(ngx, auth_header)
if api_req ~= true then
ngx.log(ngx.ERR,"Failed to validate Auth Token")
ngx.header["X-Fail"] = "mastoapi-token-invalid"
return false
end
-- Update the cache
-- We cache results for 20 seconds
cache:set(cachekey,tostring(api_req),20)
-- Authorise the request
return true
end
ngx.log(ngx.ERR,"Loaded")
if validateRequest(ngx) ~= true then
ngx.log(ngx.ERR,"Blocking unauthorised request")
ngx.header["X-Denied-By"] = "edge mastodon_api_enforce"
ngx.status = 403
ngx.exit(403)
end
A downloadable copy of this script is available at https://github.com/bentasker/article_scripts/tree/main/restricting-unauthenticated-access-to-mastodons-public-feeds/LUA
The lines adding response headers X-Fail and X-Denied-By can safely be disabled, these headers are logged and used by my WAF analysis setup.
In order to work, the shared cache needs to be enabled in the http section of nginx.conf:
lua_shared_dict mastowaf_cache 10m;
This defines a 10MB shared memory area for the shared dictionary mastowaf_cache. If/when it's full items will be LRU'd out.
Because I've deployed into a custom path, nginx also needs to be told where to look for the lua-resty-http dependency:
# Use my custom LUA directory for libraries
lua_package_path '/etc/nginx/domains.d/LUA/?.lua;;';
Finally, within the server block responsible for proxying to Mastodon I included some location blocks which define config and then define the LUA as an authentication provider
location ~* ^/api/v1/trends/(statuses|tags) {
set $origin 1.2.3.4;
set $origin_port 443;
set $origin_host_header mastodon.bentasker.co.uk;
set $origin_do_ssl yes;
access_by_lua_file /etc/nginx/domains.d/LUA/enforce_mastodon.lua;
# Do proxying stuff
}
location /api/v1/timelines/public {
set $origin 1.2.3.4;
set $origin_port 443;
set $origin_host_header mastodon.bentasker.co.uk;
set $origin_do_ssl yes;
access_by_lua_file /etc/nginx/domains.d/LUA/enforce_mastodon.lua;
# Do proxying stuff
}
I added these on my CDN, but if this were being added to the config I describe in Running a Masto Instance it would look like this
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
root /mnt/none;
index index.html index.htm;
server_name mastodon.bentasker.co.uk; # Replace with your domain name
ssl on;
# Replace your domain in these paths
ssl_certificate /etc/letsencrypt/live/mastodon.bentasker.co.uk/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/mastodon.bentasker.co.uk/privkey.pem;
ssl_session_timeout 5m;
ssl_prefer_server_ciphers On;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
absolute_redirect off;
server_name_in_redirect off;
error_page 404 /404.html;
error_page 410 /410.html;
location / {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://web:3000;
}
location ~* ^/api/v1/trends/(statuses|tags) {
set $origin 1.2.3.4;
set $origin_port 443;
set $origin_host_header mastodon.bentasker.co.uk;
set $origin_do_ssl yes;
access_by_lua_file /etc/nginx/domains.d/LUA/enforce_mastodon.lua;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://web:3000;
}
location /api/v1/timelines/public {
set $origin 1.2.3.4;
set $origin_port 443;
set $origin_host_header mastodon.bentasker.co.uk;
set $origin_do_ssl yes;
access_by_lua_file /etc/nginx/domains.d/LUA/enforce_mastodon.lua;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://web:3000;
}
location ^~ /api/v1/streaming {
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-Proto https;
proxy_pass http://streaming:4000;
proxy_buffering off;
proxy_redirect off;
proxy_http_version 1.1;
tcp_nodelay on;
}
}
With the LUA live and enforcing, I awaited the next of the thrice-hourly visits by the crawler
129.153.55.48 - - [02/Jan/2023:16:58:40 +0000] "GET /api/v1/trends/statuses?limit=40&offset=0 HTTP/1.1" 403 148 "-" "axios/1.2.1" "-" "mastodon.bentasker.co.uk" CACHE_- 0.000 mikasa - "-" "-" "-"
129.153.55.48 - - [02/Jan/2023:16:58:40 +0000] "GET /api/v1/trends/statuses?limit=40&offset=40 HTTP/1.1" 403 148 "-" "axios/1.2.1" "-" "mastodon.bentasker.co.uk" CACHE_- 0.000 mikasa - "-" "-" "-"
It now correctly receives a HTTP 403 instead of the feed.
Testing
Blocking requests was working, but I also needed to make sure that legitimate traffic was allowed through and tested the following
- Web UI: All feeds work as they should (when logged in)
- Tusky (Android): Works fine (note: doesn't have a trending view, so can't check hashtags etc, but local/federated views work fine)
- Official Mastodon client (Android): Feeds work fine
- tooot (Android): Federated/Local Feeds work fine (can't find a trending hashtags view)
Not being an Apple user, I've not been able to test iOS specific clients (though I'd hope they work much the same).
Limitations
There are some limitations, most are inherent in any instance-level block, but still seem worth enumerating
- The defence only prevents fetching of information directly from this instance. If the instance publishes to ActivityPub Relays, activity could potentially be pulled from them instead (although there is potentially still some benefit/protection from being mixed in with activity from other instances)
- If public signups are permitted, an adversary could create a legitimate account in order to use a legitimate token in their scraping requests. However, this still serves to raise the bar and they'd need to do so on every instance they wished to scrape (increasing the chance of detection)
- This only offers any protection against external scrapers: federated approaches like Mastinator require a completely different approach.
- It doesn't prevent scraping of profiles and toots in the way that
DISALLOW_UNAUTHENTICATED_API_ACCESSdoes, but also doesn't bring the drawbacks associated with that level of restriction.
Additional Protection Mechanisms
There are some additional mechanisms which can (and probably should) be considered, even though they're not specific to these public endpoints
- Basic user-agent checks: blocking empty and known bot user-agents will clear the low hanging fruit
- IP Behaviour Checks: I'm not a massive fan of IP based blocking, as it's inherently flawed, but they are popular with some - collaborative lists are generally more effective than individual manually curated lists (though not without abuse potential).
Larger Instance Admin Considerations
When it comes to blocking (or allowing) activity, admins of larger instances have much more to think about than I do.
The method that I've described has an obvious trade-off: it prevents access to public feeds by unauthenticated users.
Whilst this helps to prevent arbitrary scraping of activity, it also means that prospective users are unable to view the Local activity feed on the instance's default page, so they'll be unable to get a feel for the instance that they're thinking of joining.
The crux of the matter though, is that although unethical, anything publicly available is liable to be scraped/indexed, so raising the bar by removing unauthenticated access to endpoints that are common between different installs is not without value.
As with most moderation, it boils down to finding the right balance for your particular users.
There is a middle ground: implement a neutered version of the ruleset that logs but does not enforce.
This would allow you to build instrumentation showing how regularly these endpoints are seeing unauthenticated requests, which can then either be used to reactively add IP blocks, or to support a later decision to start enforcing the ruleset.
Cloudflare Worker Example
Although my LUA implementation should be quite easy to follow, it may not be the most useful example for admins more used to dealing with other solutions/services.
So, I decided to also create an example for use within Cloudflare's Worker system.
Be aware that there is an element of caveat emptor here: I don't use their service (as well as privacy and technical concerns, there are also various moral arguments against using Cloudflare).
This means that I've built this example entirely based on examples in Cloudflare's documentation and haven't the means to test it beyond ensuring that it's actually valid Javascript
Update: This has now, very kindly, been tested for me and appears to be working as it should.
/* Cloudflare Worker Public Mastodon API Protection
*
* Hacked together based on the following docs
*
* https://developers.cloudflare.com/workers/examples/fetch-json/
* https://developers.cloudflare.com/workers/examples/auth-with-headers/
*
*/
// The origin to send probe requests to
const api_endpoint = "https://1.2.3.4/api/v2/suggestions";
// The host header to include in those requests
const masto_host_head = "mastodon.bentasker.co.uk"
/**
* Checks for an Authorization header and (if present) uses it to send a probe
* to an authenticated origin endpoint to gauge token validity
*
* No token, or invalid token results in a 403
*
* TODO: Add caching of results to prevent repeated upstream calls
*
*/
async function doProbe(request){
// The "Authorization" header is sent when authenticated.
if (request.headers.has('Authorization')) {
// Build a probe request
const init = {
headers: {
'content-type': 'application/json;charset=UTF-8',
'authorization': request.headers.get('Authorization'),
'host' : masto_host_head
},
};
const response = await fetch(api_endpoint, init);
if (response.status == 200){
return fetch(request);
}
// Otherwise, it failed
return new Response('Invalid auth', {
status: 403,
});
}
// No auth header
return new Response('You need to login.', {
status: 403,
});
}
/**
* Receives a HTTP request and replies with a response.
* @param {Request} request
* @returns {Promise<Response>}
*/
async function handleRequest(request) {
const { protocol, pathname } = new URL(request.url);
var resp
switch (pathname) {
case '/api/v1/timelines/public': {
resp = await doProbe(request);
return resp;
}
case '/api/v1/trends/statuses': {
resp = await doProbe(request);
return resp;
}
case '/api/v1/trends/tags': {
resp = await doProbe(request);
return resp;
}
default:
return fetch(request);
}
}
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request));
});
A copy of this script is available at https://github.com/bentasker/article_scripts/tree/main/restricting-unauthenticated-access-to-mastodons-public-feeds/Cloudflare.
Current Known Scraper IPs
One of the advantages of having the LUA implementation set X-Fail and X-Denied-By is that it enables me to easily identify log lines banned by the rule, and to quite trivially enumerate hosts observed trying to hit public API endpoints without authentication.
Extracting this information, in fact, is so trivial that I don't even need to open my Grafana dashboards
grep "/api/v1" /var/log/nginx/access.log | grep "edge mastodon_api_enforce" | awk -F'\t' '{print $1,$5,$9,$18}' | sort | uniq
Which looking at results since the protection went live, gives the following
129.105.31.75 "GET /api/v1/timelines/public?limit=80&local=true HTTP/1.1" "Python/3.6 aiohttp/3.6.2" "mastoapi-token-invalid"
129.153.55.48 "GET /api/v1/trends/statuses?limit=40&offset=0 HTTP/1.1" "axios/1.2.1" "mastoapi-no-auth"
129.153.55.48 "GET /api/v1/trends/statuses?limit=40&offset=40 HTTP/1.1" "axios/1.2.1" "mastoapi-no-auth"
154.3.44.201 "GET /api/v1/timelines/public?only_media=false HTTP/1.1" "Apache-HttpClient/4.5.11 (Java/1.8.0_171)" "mastoapi-no-auth"
158.101.19.243 "GET /api/v1/timelines/public?limit=40 HTTP/2.0" "Typhoeus - https://github.com/typhoeus/typhoeus" "mastoapi-no-auth"
168.119.64.252 "GET /api/v1/trends/tags HTTP/2.0" "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)" "mastoapi-no-auth"
173.212.199.194 "GET /api/v1/timelines/public?local=true HTTP/2.0" "-" "mastoapi-no-auth"
35.232.35.2 "GET /api/v1/timelines/public?limit=40 HTTP/1.1" "python-requests/2.28.1" "mastoapi-no-auth"
46.226.110.114 "GET /api/v1/timelines/public?local=true&limit=40 HTTP/2.0" "-" "mastoapi-no-auth"
46.226.110.114 "GET /api/v1/trends/tags HTTP/2.0" "-" "mastoapi-no-auth"
87.157.136.163 "GET /api/v1/timelines/public?local=true&limit=40 HTTP/1.1" "fedi_stats/0.1.2 (by @lightmoll@social.nekover.se)" "mastoapi-no-auth"
99.105.215.234 "GET /api/v1/timelines/public?limit=500 HTTP/2.0" "-" "mastoapi-no-auth"
(I have stripped out some that were likely to identify residential users)
That first one is very interesting: it provided a token, but an invalid one.
The IP 129.105.31.75 is in a range associated with Northwestern University, if this is related to research the very least they could do is disclose it in the user-agent. It seems to visit once every 24 hours, so I may yet look into capturing more information about it.
The second thing interesting thing in the dataset is the relevant proportion of Oracle IPs - their Free Cloud Tier has obviously made them the location of choice for unwanted shit.
Because the exceptions are written into IOx, I've also been able to create a dashboard with the same list, using a simple SQL query
SELECT
DISTINCT IP, path, ua
FROM "waf_exceptions" WHERE
reason = 'mastodon_api_enforce' AND
$__timeFilter(time)

The report will improve over time (probably starting by adding the referer column helps so it's easier to spot browsing end-users).
Exception Rate
Although the rate at which scrapers scrape is quite low, the frequency at which they're observed is quite high (although this is skewed quite heavily by 129.153.55.48)

Conclusion
There are a number of external scrapers active within the fediverse (not that I expect that anyone to that particularly suprising).
Mastodon offers instance administrators a fairly coarse level of control over what information is made publicly available, via the controls Allow unauthenticated access to public timelines (limited coverage) and DISALLOW_UNAUTHENTICATED_API_ACCESS (near-total coverage, with multiple drawbacks).
Although unticking Allow unauthenticated access to public timelines disables the public Local and Federated feeds, a public feed of trending toots and hashtags remains available.
This (IMO) is a failing in Mastodon that should be rectified. Similarly, the fact that Mastodon ignores invalid authentication credentials sent to it's API endpoints is problematic, if only because it means there's inconsistency across endpoints.
The availability of the trending endpoints provides scrapers with a well known and common endpoints to request across disparate instances in order to capture an insight into activity on each of those instances.
Details of trending toots can, in some circumstances, reveal who a user follows as well as leaking information about which other instances are federated with (if toots from kinky.business start showing up on an instance with a single active user, it really doesn't take much to put 2+2 together).
The Trending Toots feed can also help indexers to identify popular posts (and posters), reducing their own operating costs (because they no longer have to index and store low value toots that no-one will likely ever search for again).
The availability of trending feeds really should be put under the control of instance administrators, seperate from the control (and associated drawbacks) offered by DISALLOW_UNAUTHENTICATED_API_ACCESS.
The approach that I've used is relatively flexible because it's deployed seperately to Mastodon: there's no need to incur the overhead of forking Mastodon and it can initially be tested without needing to make production changes (just deploy an OpenResty install/container to test with whilst getting it just right).
The worker implementation should work for Cloudflare users and provide a reference for users of other providers/services to translate from.
It may not be possible for us to completely prevent scraping without having instances turn into walled gardens, but that doesn't mean that we have to make it easy for them.