Playing Around With Automating Syndication (POSSE)

You may or may not have heard the IndieWeb term POSSE, which stands for "Publish (on) Own Site, Syndicate Elsewhere".
Although the term itself is relatively new to me, the approach that it describes is one that I've preferred for a long time.
Syndication, though, has generally been something that I've treated as a manual task: tweeting/posts links that I think are likely to be of interest (often skipping more general posts like this) and otherwise mostly relying on search engines to help people find my content.
I recently wrote a bot to consume my RSS feed and publish it into Mastodon the use of which means there's been something of a change in my approach. It's also prompted me to think about whether I wanted to automate cross-linking onto other platforms.
The aim of this post is to discuss why and how I wanted to do that (as well as to hopefully put some of my thoughts into better order).
Why POSSE?
It seems prudent to begin by explaining why I so strongly prefer writing on my own site(s), especially in a world where there's (potentially) money to be made by publishing to something like Substack.
Although it's been reinforced several times since, it all starts with my experience using a site called Helium.
If you're not interested in this bit, jump down to Implementing Syndication.
Helium
Helium was a writing and knowledge sharing site

It's usage model was quite attractive:
- The site provided titles to write content for
- You'd pick a title that you liked, research and write. Others could too
- All submitted posts would be live on the site
- Users reviewed and rated posts, with the highest rated moving up the list
- The author of any particular piece got revenue share based on daily views of that content (so you wanted your content to be highly rated)
From an author's perspective, the platform provided two things: motivation to write and a (small) source of passive income.
At one point, one author made an absolute killing because they'd shared links to their content on Digg (remember that?) and gone viral, earning an utterly ridiculous amount of money in the process (as well as subsequently generating complaints on Digg about excessive levels of self-promotion as others tried desperately to replicate his success).
I didn't earn much from Helium, but some of my posts did rank quite well
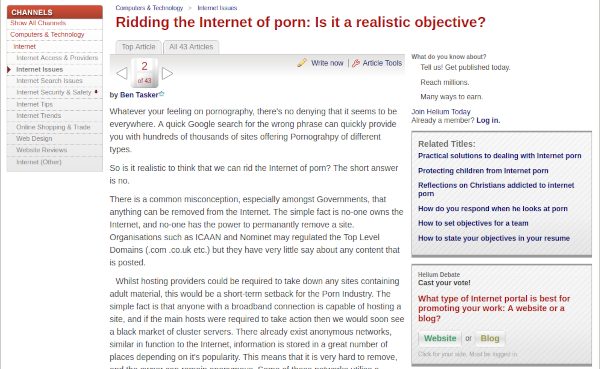
A few of my posts even achieved and maintained the top spot.
Initially, I was very happy using Helium.
The range of topics and the provision of specific titles allowed me not only to write on topics I knew well, but also to periodically step outside of my comfort zone and research/write about something new. I even tried my hand at poetry (It's hard to put into words just how much you don't want to see the results - I think the best rank I achieved was 12 out of 99).
Basically, there were lots of interesting challenges, with each effort contributing a little bit towards a (very) small passive income.
All too soon though, things changed and the company announced that to receive revenue share, authors had to have reviewed at least a set number of posts each day. I can't remember the exact number, it wasn't huge, but still high enough to be extremely inconvenient to someone who was already quite timestrapped.
I remember it feeling extremely unfair: Helium were still deriving revenue from existing posts, but were no longer sharing that revenue unless you were able to spend time daily meeting the new requirement that they'd unilaterally introduced.
With the revenue share being quite small, it also didn't really make any financial sense: reviewing posts was quite time-consuming, so authors were effectively working for pennies an hour (and with no way of knowing if they'd earn anything for that day's work or not).
I wasn't alone in this discomfort, it alienated quite a lot of the community. Inevitably, the quality of reviews also took a hit as authors rushed through in order to try and meet their quota to protect their daily revenue share.
I stopped using Helium shortly after the change was introduced. As much as I'd enjoyed the challenges it had previously provided, the change (and the way that it was delivered) felt like a significant breach in trust and I didn't feel comfortable helping them to derive additional revenue off the back of my work.
Control of Content
If I'd had the option, I would probably have deleted the content I'd already posted to Helium. It wasn't an option though, although the work was credited to my name, I lost control of that content the minute I posted it.
In the time that's passed, I've now also lost most of that content entirely.
Unfortunately, I didn't think to take copies of most of it (what I did take was lost for a time, as the result of hardware failure, the few bits that I have managed to find/recover are on this site tagged under Helium) and so, with Helium's demise, I no longer have access to some work I remember being quite proud of (although there's undoubtedly an element of rose-tinted glasses).
The Wayback machine captured some of that content, but Helium used to automatically paginate (presumably to help drive up ad impressions) and Wayback has generally only captured the first page. The domain itself, nowadays, is occupied by the Helium Cryptocurrency and Helium Inc has long since ceased to be.
I was drawn into publishing on Helium by exciting challenges and a promising revenue model, but in doing so relinquished control of my work.
Ever since, almost everything that I've written in my free time has been posted to one my sites. For a while, I derived revenue by serving ads alongside, but was never quite comfortable with the privacy implications (my last experiment with ads ended in 2021).
There are a wide ranges of content hosting services and platforms available, many of which offer attractive revenue opportunities, but almost all come with an implicit risk: the terms of the arrangement can (and probably will) change, potentially resulting in your content being locked in a silo out of your control (hell, at times, even your face hasn't been safe).
Implementing Syndication
It's fair to say that, for me, the primary motivation for posting to my own sites is to ensure continued ownership of content.
But, this does come at a cost to discoverability. Most eyes are firmly focused on content within the various Social Media silos and so there really is a need to ensure that your content (or a link to it) is discoverable for those users (even if only as a link back).
The next thing, then, is to look at approaches to automating that syndication.
Triggering Syndication
Users of dynamic content management systems (CMS) like Wordpress will generally find this quite straightforward: there are a wide array of plugins available, each of which can trigger when content is published.
However, I'm not a Wordpress, or even a dynamic CMS, user.
For most of my sites I use a static site generator called Nikola. Creating (or finding) a Nikola plugin to crosspost content would probably be quite straightforward, but where possible I prefer software-agnostic solutions (not least because not all of my sites are using Nikola).
The one thing that (most of) my sites have in common? RSS feeds.
RSS is also what my Mastodon bot relies on, so there's an additioanl benefit in that building an implementation around feeds would mean that my various syndications would all come from a common source (which is handy when troubleshooting).
Consuming the feed
Writing my Mastodon bot was intended as a learning exercise: it gave me a means to play around a little with Mastodon's API and get a feel for it. I don't really have the same need (or desire) to learn and deal with the APIs of sites like Twitter and LinkedIN.
More importantly, in order to obtain an API key, Twitter requires that you provide a verified phone number:
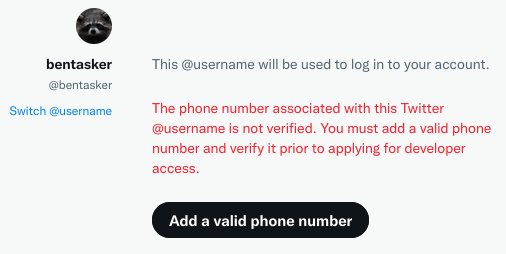
This isn't something I'm going to do: Arbitrarily requiring phone numbers is a bad idea, and Twitter in particular has form for misusing data held for a different purpose even before you consider the ramifications of Musk's takeover on Twitter's ability to protect data.
So, rather than self implementing, I wanted a turn-key solution: to use something that had already overcome the various barriers and supports as wide a range of social networks as possible.
Although I last used them years ago, I decided to give If This, Then That (IFTTT) a try and in order to have somewhere to test against, also created a sub-reddit: /r/bentasker.
I created an IFTTT applet to read my RSS feed and post new items into /r/bentasker

All the test attempts worked, so I set it live.
Inevitably, it took ages for me to get around to writing a new post, but when I did, it automatically appeared in the subreddit.
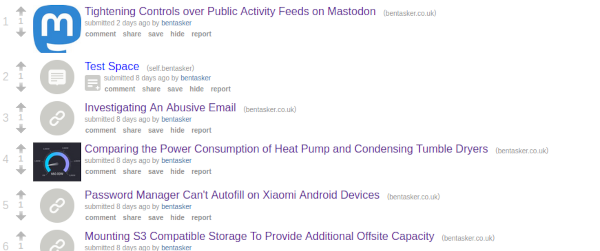
Not many people are likely to actually see the sub: I don't really use my bentasker reddit handle and so there's very little chance of someone stumbling upon it as the result of me talking in another sub, but it proves the workflow is working.
Syndication Destinations
Having set up publishing into reddit, I couldn't see much point in turning it off, so continue to publish into that sub.
Posting everything into a single sub isn't quite what the IFTTT applet author is likely to have had in mind. Really the intent was probably to identify feed items on a specific topic and crosspost into something like /r/tech, which is something I might look into later.
IFTTT does have an applet for posting to facebook, but I'm not planning to enable it: I stopped using facebook a long time ago and have no particular desire to feed the beast.
Since Musk's disaster of a take-over, I've some concerns over having my content available on Twitter. However, I do have automated tweet deletion enabled and so probably will enable automatic cross-linking at some point soon.
LinkedIN is where I was initially left a little undecided.
I've always viewed LinkedIN as being more of a professional social network (even if not everyone always acts like it), primarily used for recruitment and job hunting purposes.
So, I might want to be a little bit more discriminate about what gets automatically pushed into LinkedIN, raising the question of where (and how) you draw the line.
For example, if we take a handful of recent blog posts and consider their suitability:
- Tightening Controls over Public Activity Feeds on Mastodon: provides security analysis and solutions, probably good to post
- Comparing the Power Consumption of Heat Pump and Condensing Tumble Dryers: provides analysis, but is it actually likely to be of interest to the average LinkedIN user? Probably not, so bad to post
- Adding WebMention Support to Nikola: demonstrates how to do something, possibly useful for businesses, probably good to post
- Analysing Clearnet, Tor and I2P WAF Exceptions using InfluxDB IOx: demonstrates investigative techniques as well as technology, probably good to post
- Investigating An Abusive Email: demonstrates investigative techniques, good to post, but quite sweary - bad to post?
The final point might feel like pearl clutching, but it's potentially important when job-hunting (IMO, still the primary purpose of LinkedIN).
I once had a recruiter that I make a Github repo private because he felt that prospective employers might be sensitive to some of the language used (If you're not familiar with AMP and are wondering whether that use of language is warranted, it absolutely is).
Apparently the recruiter had seen an employer withdraw an offer from a candidate after discovering something vaguely similar.
Whilst there's an argument that a mature employer recognises that they're hiring a complete person and isn't going to be that bothered, it's also probably wise to not automate posting of content which might make recruiters less willing to work with you.
Implementing that requirement though, does make things more difficult.
Selecting each of the other example posts can easily be achieved using the tagset. However, differentiating between "Analysing Clearnet, Tor and I2P WAF Exceptions using InfluxDB IOx" and "Investigating An Abusive Email" is much harder: they're both on "shareable" tags, it's just that the text of one happens to include profanity.
If I was laying code to handle syndication, it'd probably be a case of checking post content for naughty words (though solving things like the Scunthorpe Problem isn't as straightforward as it sounds), but we're using an existing solution which lacks that capability.
Really, then, we're left with 3 options
- Maintain the status quo and don't syndicate into LinkedIN
- Syndicate everything
- Only syndicate content with a LinkedIN specific tag
Option 2 isn't particularly appetising, more because of concern about sending topics that won't be of interest to people there than it is to do with the presence of profanity.
The final option seems to be the way to go, even if something of a trade-off: the process would no longer be fully automatic (I'd need to remember to add the special tag), but it does removes the need to log into LinkedIN and manually post a link.
Because Nikola supports creating hidden tags it's possible create purely functional tags without needing to pollute tag listings with them.
HIDDEN_TAGS = ['to-linkedin']
With the tag created, setup is easy: IFTTT watches the tag specific feed for to-linkedin and when new content appears under that tag, a link is automagically published:
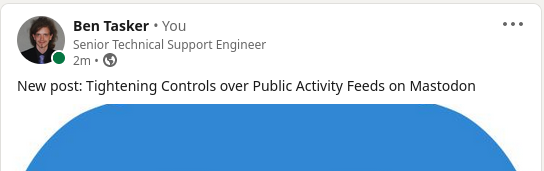
Conclusion
Having previously lost control of content, I much prefer to post content to sites under my own control.
This does make discovery a little more difficult, as modern users tend to be concentrated onto a small set of platforms such as the social media networks.
For sites with an RSS feed, setting up automatic syndication to post links into those networks is easy and solutions such as those provided by "If This, Then That" provide an accessible (and no-code) means to enable automatic cross-linking across a wide range of platforms.
The hardest bit, really, is in deciding what you want to syndicate into certain networks. Once that's decided, so long as your publishing software exposes a feed per tag (or category) you can use that capability to mark posts as being suitable for specific networks (with the added benefit that, if desired, you can stagger release across networks).
It'll probably take some time, but it'll also be interesting to see whether having automated syndication makes a meaningful difference to traffic volumes attributed to the various referral sources
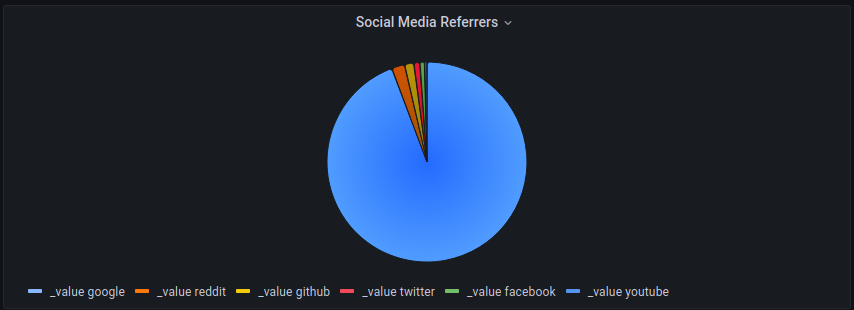
Currently, visits from most social media sources pale in comparison to visits resulting from Google searches.
At the very least, hopefully LinkedIN will start appearing on that chart a little more frequently.