Mounting S3 Compatible Storage To Provide Additional Offsite Capacity
I basically live inside text files: my notes are in text files, the systems I work with generally use text config files and this site uses Markdown under the hood. Such is my preference for plain text that some of my project tracking even has a hidden text format output.
As a result, I've acrued quite a collection of text notes over the years, even if most aren't in a form which could be published

I'm not hoarding notes simply for the sake of it: I do occasionally refer back to older tasks (although sometimes it is for really odd things, like recently digging out my 2018 notes on the Mythic Beasts Job Challenge to see how it had changed over the years).
Plaintext has various advantages over something like OneNote, particularly in terms of ensuring ongoing accessibility and compatability. But, of course, also has it's own costs: searchability being a big one.
Searching with grep works, but only up to a point. Aside from not having things like stemming, once you've been keeping notes for over a decade, you do tend to find that at some point you crossed a line where grep is no longer able to quickly give meaningful results, particularly if you've also got non-text files mixed in.
I addressed the searchability issue by deploying a search engine: I initially used Sphider, then a self-maintained fork of it, before eventually rolling my own Elasticsearch based one. I wrote about some of my experiences with the latter a little while back, but generally does what I need
Those years of content, although now searchable, consume space. Sooner or later storage gets tight (something that's only hastened by also storing media collections and the like).
Inevitably, an alert triggered this week: I'd consumed 86% of available storage so it was time to start thinking about adding (or freeing up) space.
After a very quick look, I decided that more storage was in order. But, I also didn't want to shell out for new hard-drives (or add to our power consumption) and so decided to look at the viability of mounting some remote storage instead.
This post goes over the process that I followed.
Storage Options
There were a couple of possible storage options to choose from.
I could have chosen to spin up a cloudy VM, attach storage volumes and use NFS (over VPN) to access them. This would be quite convenient because my main NAS (a DS220) can mount and re-export remote NFS shares.
But, the costs don't really add up, because as well as paying for the storage, I'd need to pay for (and maintain) the VM itself.
The second option was Object Storage.
It's usually cheaper per-GB and also doesn't carry the VPS cost overhead because you interact directly with the storage via API.
Object Storage is also quite a competitive market, with many providers supporting some level of interoperability by providing an API compatible with that provided by the market's resident 100lb gorilla: Amazon's S3.
The broad range of providers supporting that API means that switching between providers should be relatively straight-forward: copy the files to the new provider and reconfigure the client to point to them. In fact, you even have the option to move to self hosted/managed by deploying MINIO as the API provider.
Although there are quite a few to choose from, I considered 3 providers
Backblaze really is shit-hot at the moment: lots of people have mentioned using B2 as storage for their Mastodon servers and their pricing certainly makes them attractive.
So, I considered them quite strongly, but - for now - they're too much of an unknown. I've got pre-existing accounts with both AWS and DO, so there's a level of familiarity there. I am going to find a project to use B2 in to help build up that familiarity and trust, but this isn't the project for that.
DigitalOcean's pricing is also pretty good
- Starts at $5/month
- 250GiB storage ($0.02/GiB for additional)
- 1TiB Outbound transfer ($0.01/GiB for additional)
Clarity of Communication
Not only is it cheaper than AWS's offering (assuming you use the storage), but DigitalOcean's pricing structure is much clearer than S3's and provides a measure of certainty that Amazon does not: the monthly bill will be $5 a month until the storage use or egress traffic grows beyond the bundled allowances.
Although not a driver of purchasing choice, it's also worth noting that the difference in clarity even carries over to the way the two providers describe the units they bill by on their relative pricing pages:
- Digital Ocean storage:
$0.02/GiB - AWS storage:
$0.023 per GB
Digital Ocean's unit of measure is clear: they charge $0.02 per Gibibyte (1024 Mebibytes).
Amazon's pricing unit, however isn't. Do they mean $0.023 per 1000 Megabytes or per 1024 Mebibytes?
The answer is buried in the footnotes

So AWS also charge per Gibibyte, but for some reason haven't seen fit to use the correct notation in their pricing table.
<soapbox>
I know that many of us were brought up with 1GB being 10243 bytes, but seriously, GB has meant 109 for nearly a quarter of a century, and all of the current millenium (109 was formally adopted in December 1998).
Even in the US, with it's habit of using drunken mathematician units, the courts found that
{kind=link}
the U.S. Congress has deemed the decimal definition of gigabyte to be the 'preferred' one for the purposes of 'U.S. trade and commerce'"
The decimal definition being 109 (1GB = 1000 Megabytes).
There really is no good reason for Amazon to have used the wrong unit, it's wrong even by American standards.
</soapbox>
Design
Content is served to the LAN via a nginx install on my old NAS (holly). Whilst there's no reason that reads couldn't be implemented by having nginx proxy through to the Spaces endpoint, it wouldn't address the need to be able to write into the Space
Whilst writing this, I've realised how much I dislike that they're called spaces. In a conversation about storage capacity it's somewhat ambiguous and feels wrong. I'll refer to them as buckets from here on out.
To keep writing simple, I wanted the bucket to be mounted locally, exactly the use-case that s3fs is designed to satisfy.
The intended topology, therefore was
------------
| DO |
| SPACES |
------------
|
t'internet
|
------------
| s3fs |
------------
|
------------
| Nginx |
------------
|
------------------
| LAN Clients |
------------------
|
|
O
\_|_/ <--- Me, confused
| trying to remember why
_/ \_ I did things that way
Fairly simple really.
Containerisation
It's been a long time since I last used s3fs. In fact, my last use of it appears to be from before I'd properly developed my note-keeping habits, so search only finds one passing reference to using wget to fetch version 1.19 from googlecode.
I do remember that I initially had various issues with it and that updating was really quite disruptive (especially if the updated version decided not to work for some reason).
Although it will (obviously) have improved significantly since, the re-emerging memories of that project pushed me towards using a container to try and mitigate some of the upgrade related headaches (with containers, you can spin up a second container to test the new version without impacting the first).
Containerisation also brings a number of other benefits
- Monitoring bandwidth and resource usage is extremely easy: I already have the docker input plugin configured in Telegraf
- We're dealing with a remote provider (no matter how trusted), so process isolation is welcome
- Dependencies are handled: everything needed is already rolled into the container's image
The only requirement is that Docker must be newer than version 1.10 (because that version added support for sharing the host's mount namespace). 1.10 was released back in 2016 so the bar isn't set particularly high.
Setting up the Space
Now that I had an idea of what I wanted to do, and how, the first thing to do was to create the storage and mint some keys to grant access to it.
I logged into DigitalOcean's cloud control panel, chose Spaces and started creating the Space/Bucket

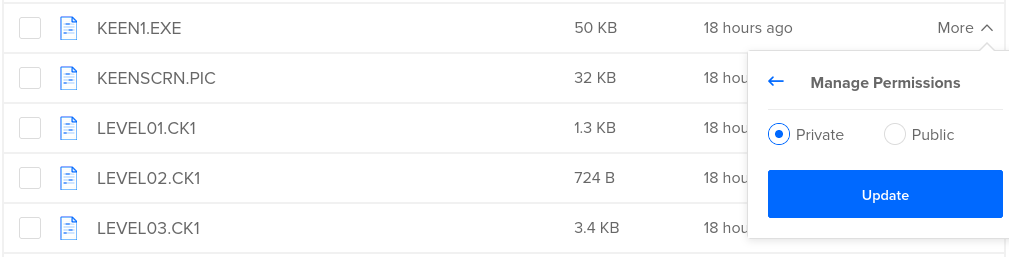
Files shouldn't be publicly available, so I left CDN disabled and selected Restrict File listing.
The warning in the screenshot is a little disconcerting
Important: This setting has no effect on whether individual files are visible. It only determines if anonymous users can list the name, size, and other metadata for files in this Space.
Data being accidentally stored in public S3 buckets is a huge issue in the industry and obviously we don't want to make the same mistake. What the note doesn't say though, is what the default state of any given file is.
Thankfully, it's sane: private
As part of the creation process you provide a (globally unique) subdomain and the URL for the space is calculated automagically

We'll need this URL (or part of it) later
Creating Credentials
With the Space created, we need credentials to be able to access it.
For some reason, DigitalOcean don't seem to link to the relevant documentation from within their web interface, but setup is fairly easy once you know how.
Log into the Cloud Console and choose API on the left, then scroll down to Spaces access keys

Click Generate New Key
Provide a name, click the tick and you'll be presented with the key and it's secret.
Make a careful note of these, because you won't be able to view the secret again.
s3fs Deployment
We now need to be able to mount the bucket onto a system on the LAN.
The container works by writing into the host's mount namespace, so we need to create a mountpoint for it to use
sudo mkdir /mnt/s3fs
sudo chown ben /mnt/s3fs
All that remains is to run the s3fs container to bring the mount online.
To construct the necessary docker run command, we need
- The space/bucket name
- The generated bucket URL, but with the bucket name removed (e.g.
https://dospace1.fra1.digitaloceanspaces.combecomeshttps://fra1.digitaloceanspaces.com) - The generated access credentials
With those details, we run the following command
docker run -d \
--name=s3fs \
--restart=always \
--device /dev/fuse \
--cap-add SYS_ADMIN \
--security-opt "apparmor=unconfined" \
-e AWS_S3_BUCKET=<space name> \
-e AWS_S3_ACCESS_KEY_ID=<access key> \
-e AWS_S3_SECRET_ACCESS_KEY="<secret>" \
-e AWS_S3_URL="<amended url>" \
-e UID=$(id -u) \
-e GID=$(id -g) \
-v /mnt/s3fs:/opt/s3fs/bucket:rshared \
efrecon/s3fs:1.91
With that, the space should be mounted.
From the host, we can test this by touching a file
touch /mnt/s3fs/foo
The file should then be visible in the Spaces section in DigitalOcean's web console.
If all is well, files can now be copied and read from the mount point as needed: everything's up and running.
Well, Akshually...
In reality, I wasn't quite done yet.
Earlier in this post I mentioned a couple of important points
- Nginx runs on my old NAS (
holly) - The
s3fscontainer requires Docker >= 1.10
Unfortunately, holly still runs Debian Jessie (naughty) and the version of docker available in the archived apt repos is 1.5. Although s3fs can be installed with pip, unsurprisingly, it's now all written in Python 3 (and Jessie is very much stuck with Python 2), so that's a no-go.
It simply isn't possible to reliably deploy a modern version of s3fs onto the NAS and the OS can't be upgraded to address that (although it needs doing, I'm not quite ready to start decommissioning it yet).
So, instead, I needed to deploy s3fs on a different machine and give the NAS access to it. The result is that my topology has an additional step
------------
| DO |
| SPACES |
------------
|
t'internet
|
------------
| s3fs |
------------
|
sshfs
|
------------
| Nginx |
------------
|
------------------
| LAN Clients |
------------------
|
|
O
\_|_/ <--- Me, confused
| trying to remember why
_/ \_ I did things that way
The s3fs mount is on another system (thor), and holly uses sshfs to access it. I initially played around with having thor expose the s3fs mount via NFS, but it didn't want to play (files could be written into the share, but were written to thor's filesystem rather than DigitalOcean - presumably being written in under FUSE).
Setting up a sshfs mount is pretty straightforward:
sudo apt-get install sshfs
# Make a mountpoint
# could be anything but keeping consistent
sudo mkdir /mnt/s3fs
sudo chown ben /mnt/s3fs
# Do the mount
sshfs -o idmap=user thor:/mnt/s3fs /mnt/s3fs
The mount came up straight away with both reads and writes working.
I looked at configuring automounting with autofs, but it was also quite determined not to work properly. It looks like it's probably an issue in the jurassic version of autofs in Jessie's repos (again, this is why you don't run decrepit software in prod).
Eventually, I accepted defeat and instead updated /etc/rc.local with a call to mount the volume
su ben -c 'sshfs -o idmap=user -o allow_other thor:/mnt/s3fs /mnt/s3fs'
So that the volume is remounted following a reboot.
It's a layer on self-inflicted unnecessary complexity, but the bucket can now be "directly" written to and read from on holly.
Nginx config
There's nothing special required of NGinx, but this post didn't feel complete without there being some kind of example.
In order to serve the files I was testing with, I created the following nginx config
server {
listen 80;
server_name dosgames.holly.home;
root /mnt/s3fs/DOS_Games/;
index index.html index.htm;
location / {
try_files $uri $uri/ =404;
}
}
One quick reload
systemctl reload nginx
And files could be fetched with curl.
Mount Behaviour
One of the things I wanted to double check, was how the mount behaves for metadata requests.
My search engine spider places a HEAD request for each path in order to see whether it serves an acceptable filetype (and, for previously indexed content, whether it's Last-Modified or Etag have changed). I wanted to be sure that HEAD requests wouldn't result in s3fs fetching the full file (otherwise we'd waste a lot of bandwidth and time).
The easiest way to check was to place a HEAD request against a larger file. If the response came back quickly, there could be no full file transfer involved, if it took a while, it'd suggests that at least some of the file is being fetched from storage.
curl -I -H "Host: dosgames.holly.home" http://holly/BarneySplat_DOS_EN_v001.zip
HTTP/1.1 200 OK
Server: nginx/1.6.2
Date: Thu, 22 Dec 2022 07:42:22 GMT
Content-Type: application/zip
Content-Length: 40656
Last-Modified: Wed, 21 Dec 2022 15:02:19 GMT
Connection: keep-alive
ETag: "63a31ffb-9ed0"
Accept-Ranges: bytes
The response was very fast (subsecond in fact), the file was not being fetched unnecessarily.
The combination of sshfs and s3fs does mean that GET requests behave a little oddly: both of the FUSE filesystems appear to buffer chunks, so although files are served quickly, throughput is quite bursty.

(If you've never played Biing, it's like a much harder, more adult Theme Hospital)
If the fluctuations do prove to cause issues, though, I'll spin up an Nginx container on thor so that it can access the s3fs filesystem directly and have Nginx on holly proxy through to that. There'll still be some buffering, but at least then there'll only be a single layer of it.
Metrics
Because s3fs is running in docker, my existing docker dashboard can be used to show it's resource cost
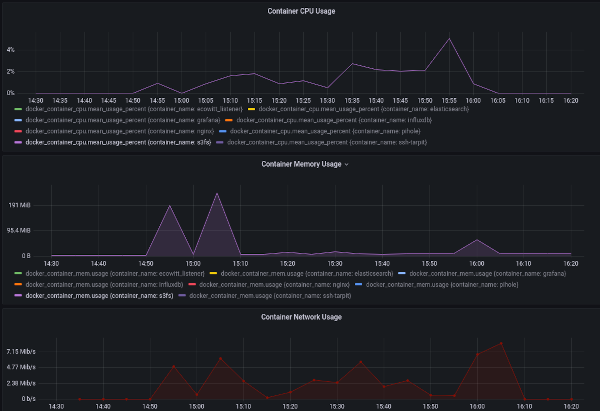
It's resource overhead is low enough to be barely worth noting.
Conclusion
The presence of old hardware made things a little harder (meh, self-inflicted pain), but mounting S3 compatible storage onto a local device is really quite simple: s3fs provides seamless access to a remote bucket with very little in terms of resource cost.
If I later want to change provider (or even move back to self-hosting), I can trivially pivot to using any service so long as it provides a S3 compatible API.
Like most networks, my LAN has changed over time and not everything has managed to keep pace. Although most content is stored on my newer NAS, the old NAS - holly - is still very much in active duty, despite being tied to an increasingly ancient OS release.
sshfs allows that older system to access the s3fs mount, helping to once again kick the can of deprecated-hardware down the road until I have the spoons to start thinking about actually decommissioning it.
In reality, it's not actually just the NAS that needs review, readers may have noticed that even my naming system is outdated and inconsistent. Originally, nodes were named after Red Dwarf characters, but at one point I'd created so many VMs (and foolishly used a name for each) that I ran out and had to move onto another franchise.
I also, somewhat foolishly, let family name their own kit, meaning that names on the LAN are now a mix of Red Dwarf, Transformers, Pokemon and Marvel.
Fixing that, much like upgrading the NAS, is a project best left for some other time.