Tuning Pi-Hole to cope with huge query rates

As some may already know, I offer a small public encrypted DNS service at dns.bentasker.co.uk, offering DNS resolution via DNS-over-HTTPS (DoH) and DNS-over-TCP (DoT).
The setup I use is an evolution of that one I described when I published Building and Running your own DNS-over-HTTPS Server 18 months ago, providing ad and phishing blocking as well as encrypted transport.
It was never intended that my DNS service take over the world, in fact, on the homepage it says
A small ad and phishing blocking DNS privacy resolver supporting D-o-H and D-o-T .... This service is, at best, a small hobby project to ensure that there are still some privacy-sensitive DNS services out there.
Not all nodes in my edge even run the DNS service.
The service has always seen some use - much more than I really expected - with queries coming in from all over the globe, and query rates are pretty respectable as a result.
However, recently, query rates changed, and there was such a seismic shift in my daily graphs that the previous "routine" usage started to look like 0:
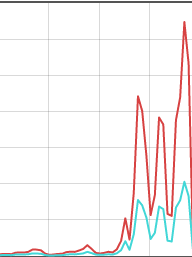
I'm omitting figures and dates out of an abundance of caution, but the lines represent usage across different days (the vertical grey lines each denoting a day)
You can see that usage increased by several orders of magnitude (the turquoise line is the number of advertising domains blocked, so usually increases roughly proportionately).
The change in traffic rates triggered a few things
- Alarms/notifications from my monitoring
- Notifications from some of my connectivity providers to say they were mitigating an apparent DoS
This post is about the (very few, actually) minor things I found I needed to do to ensure Pi-Hole could keep up with the new load.
What Changed?
Obviously, it'd be remiss of me not to see a drastic increase in query rates and not do some basic investigation/analysis to check that this was genuine usage. I log minimal information for DNS queries and this really was the first "in anger" test of whether it'd be enough.
I'm going to err on the side of caution and not give too much information here, in order to protect the users. I'm not used to doing deliberately vague write-ups, so hopefully what follows won't be too unreadable.
Checking my access logs, I could see that a huge bulk of queries was coming from a tiny handful of subnets (but spread across addresses within those subnets). These subnets belong to the state (and I believe, only) ISP of an extremely authoritarian country.

A quick look at the names being queried showed that there was a lot of usage for sites that you or I would consider "normal" but are banned in that country - Facebook being a popular example. We're not talking about a bunch of dissidents visiting "howto.overthrowgovt.com" but instead a userbase that's simply trying to access information that we take for granted.
High Connection Rate
The user-agent being logged for DNS-over-HTTPS requests looked perfectly legitimate (being the name of a popular DoH app), but checking the logs with grep and awk seemed to show a near 1:1 relationship between connections and requests - HTTP Keepalive's weren't being used.
As a result, the rate of new connections was huge, and the (already large) conntrack table was filling
nf_conntrack: table full, dropping packet
This also meant, of course, that there were a lot of SYNs flying about on the network, which is why my connectivity provider's respective systems had flagged this a DDoS - with the change in trend, some packets not being responded to (because they were dropped), it looked a lot like a SYN flood.
A bit more poking around and analysis strongly suggested what I'd started to suspect - the IPs I was seeing weren't directly the users themselves, but those of the ISP's NAT pool(s) - this was a large volume of users sat behind a relatively small set of IPs.
Some loglines showed what look like typos in the path (trailing spaces, q's miscopied as g etc) consistent with the idea that the config to use my service was being passed around amongst users rather than coming from singular central source, I'll come back to this tangent a little later.
So, to summarise, the changes that now needed to be handled were
- Massive increase in DNS query rate
- Massive increase in connection rate
- Corresponding increase in network traffic
System
As I alluded to above, the conntrack table started filling, meaning that packets were getting dropped left right and centre. So, I doubled it's size, setting the sysctl netfilter.nf_conntrack_max accordingly.
This seemed to be enough to help keep us ahead of the massive rate of connection cycling.
Pi-Hole
To begin with, there weren't any major concerns - Pi-Hole seemed to have handled the uptick in traffic reasonably happily and things were chugging along.
However, some of my nodes were undersized for the volume of connections they were handling, so I wanted to make some more physical resources available to them - extra RAM, additional CPU cores etc.
This is where Pi-Hole came a bit unstuck.
I'd kicked a box in my edge out of service, waited for traffic to drain and then rebooted to bring the new resources online.
Except, when it came back up, it wouldn't answer queries.
Pi-Hole's process was running, but it was just sitting there, and PiHole-FTL hadn't bound to UDP 53.
Pi-Hole's logfile (/var/log/pihole.log) was getting hammered with lines like
[2020-09-29 14:39:40.445 3594] Resizing "/FTL-queries" from 107577344 to 107806720 [2020-09-29 14:39:45.746 3594] Resizing "/FTL-strings" from 286720 to 290816 [2020-09-29 14:39:50.327 3594] Resizing "/FTL-queries" from 107806720 to 108036096 [2020-09-29 14:39:58.947 3594] Resizing "/FTL-queries" from 108036096 to 108265472
A bit of hunting around on the net revealed that Pi-Hole wasn't hanging, it was in the process of starting up - it's just that the previous query rate meant the DB was massive, and it was trying to re-import it.
So, the first change that was needed was (in /etc/pihole/pihole-FTL.conf)
DBIMPORT=no
In Pi-Hole's config - this allowed Pi-Hole to start, at the cost of not having stats available from prior to the restart.
The system was able to handle queries again. However, soon enough, those lines started appearing in the log again (and, at a hell of a rate) as Pi-Hole struggled to keep up with maintaining the current multi-GB DB.
So, ultimately, I decided to disable the DB entirely
MAXDBDAYS=0 PRIVACYLEVEL=4
This had a couple of positive effects. Firstly, it free'd up some CPU time (as there was no longer any need to tidy the database), but it also helped slow the rate at which the logging partition was being filled - we were no longer writing out "Resizing" loglines constantly.
Stats
However, there was also a negative effect - it killed the stats collection used to generate the graph in the intro to this piece, which had previously just pulled query counts from Pi-Hole's API:
url = "http://127.0.0.1:8080/admin/api.php?overTimeData10mins"
try:
req = urllib2.Request(url,None)
f = urllib2.urlopen(req, timeout=20)
except Exception as e :
print "Failed to connect to %s" % (url,)
data['reachable'] = 0
traceback.format_exc()
return False
response = f.read()
try:
s = json.loads(response)
return response
except:
return False
So, I needed to adjust so that statistics would be pulled from the logfile instead, and write that out in the format that Pihole's API was originally returning the data in.
Because the logfile was getting to be huge, I decided I'd collect stats with a granularity of 1 hour, rather than the 10mins I'd had before - annoying, but it felt like a sane trade-off.
# Calculate time 2hrs ago, then 1hr ago
for N in hours:
date_N_hrs_ago = now - timedelta(hours=N)
epoch = date_N_hrs_ago.strftime('%s')
# Turn that into the correct format
grep_time = date_N_hrs_ago.strftime("%b[ ]+-%d %H:").replace("-0", " ")
# Run the check
# Get the line counts for that hour
cmd = ['grep -P "^{}" /var/log/pihole.log | grep ": query" | wc -l'.format(grep_time)]
queries = subprocess.check_output(cmd, shell=True)
cmd = ['grep -P "^{}" /var/log/pihole.log | grep ": /etc/pihole/" | wc -l'.format(grep_time)]
ad_count = subprocess.check_output(cmd, shell=True)
# Push the stats
domains[epoch] = queries.strip('\n')
ads[epoch] = ad_count.strip('\n')
# Build the JSON check_output
j = {
"domains_over_time": domains,
"ads_over_time": ads
}
These changes meant that Pihole was able to run at full-tilt, whilst still allowing me to collect stats in order to monitor the rate at which queries were being received.
The effect of all this was a slight increase in query rate - presumably we were bottlenecking slightly on something, causing queries to be abandoned before they hit Pi-Hole (and so not being represented in the logs/stats).
Typo'ed paths
This is a slight tangent from what I originally wanted to post about, but it feels like something worth discussing, in case it helps shape config/design on other services/apps.
As I noted before, I observed various typo's in the path, resulting from misconfiguration at the user's end. Rather than placing requests against the path /dns-query I saw some users request against paths such as
/dns-query%20/dns-guery/dns-q...
Some of these look consistent with config being shared via messenger/forum posts - in particular /dns-q... looks like it's been copied from a message that's been truncated for being too long.
Regardless of how they came about, though, they all pose something of an issue.
Those paths were repeatedly observed, so this doesn't appear to have been a case of a user trying config, finding it didn't work and then correcting it, their systems were configured to use an invalid path and the user hadn't noticed.
Now, this is potentially quite dangerous.
Many DoH clients (Google's Intra included) will fall-back to using native DNS (i.e. sending it via the user's ISP) if DNS-over-HTTPS resolution fails for a query.
The idea being that if you've got names that only resolve on your LAN, they'll fail to resolve over DoH, fallback to your local resolver and then you can still access them.
However, if you're a user in an authoritarian state trying to circumvent state censorship, the consequences of this DNS leakage may be extremely severe (threatening liberty, or perhaps even life).
Whilst a user in that sort of situation needs to take ultimate responsibility for ensuring they've not misconfigured, having noticed the issue there is something we can do to help mitigate: have Nginx be a little more greedy about the paths it'll accept DNS queries on
location ~ /dn(.*)$ {
limit_req zone=dnslimit burst=30;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-NginX-Proxy true;
proxy_set_header Connection '';
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_redirect off;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_read_timeout 86400;
proxy_pass http://dns-backend/dns-query$is_args$args;
proxy_hide_header X-Dont-Cache-Me;
proxy_hide_header X-Powered-By;
proxy_hide_header Server;
}
This location block will catch any path starting with /dn and pass it through to the back-end using the correct path, a small price to pay if it helps risk reduce of DNS leakage at the client's end.
If you're following along and wondering why I've explicity passed the querystring through rather than letting nginx auto-append it, it's because not doing so in a regex location block (whilst using a fixed path on the origin) leads to Nginx erroring with "proxy_pass" cannot have URI part in location given by regular expression.
Conclusion
I'm using Pi-Hole some way out of it's intended comfort zone - it's designed to provide service within the confines of a LAN, rather than as a generally available service (albeit with a shim in front of it). It definitely wasn't intended to be used to serve queries for a %age of an entire country's userbase (even it's DNS resolver's parent project - dnsmasq describes itself has providing "network infrastructure for small networks").
Despite that, it coped admirably with a percentage uptick in traffic which would make most small service providers weep. Even the changes I had to make are actually pretty minor in the scheme of things, really not too shabby at all.
I'm sure, with time and effort, it'd also probably be possible to find alternatives to disabling the DB entirely - perhaps even something as simple as moving the underlying sqlite DB onto a ramdisk, though as I've only ever really used the admin page to pull stats, I'm not overly concerned by it.
My DNS service was built in order to provide privacy - both in terms of the encrypted transport and the ad blocking - rather as a tool to circumvent draconian states.
Whilst it's encrypted nature means that it can be used for the latter, there's a real danger - to the user - in using a service not designed with that threat model explicitly in mind, because potential leaks and misconfigurations can carry real-world consequences. Failed queries, whether due to rate-limiting, client misconfiguration or service overload, can all potentially lead to DNS leakage.