Monkeying about with Pyodide and PyScript

Earlier in the week, I saw an article about running Python in the browser via a port of the Python interpreter to WebAssembly.
I couldn't think of an immediate need for using it over Javascript, but often learn unexpected things when playing around with new technologies, so I wanted to have a play around with it.
An obvious start point for me seemed to be to see whether I could use the Python InfluxDB Client to connect to InfluxDB Cloud and query data out.
This proved to be more challenging than I expected, this post follows the process of tinkering around with Pyodide and Pyscript in order to get the client running and ultimately build a semi-interactive webpage that can query InfluxDB using Python in the browser.
The Console
Although the project I'd heard about is Pyscript, it's based on Pyodide which provides a console/REPL that you can use (https://pyodide.org/en/stable/console.html).
So, out of convenience, I started with that.
The Client
There's documentation on installing and using the InfluxDB Python Client at https://docs.influxdata.com/influxdb/cloud/api-guide/client-libraries/python/ and a normal installation would be as simple as
pip install influxdb-client
But, an in-browser script is obviously going to require a different approach.
Pyodide provides micropip which can install anything that pip can subject to the qualification given in the docs
This only works for packages that are either pure Python or for packages with C extensions that are built in Pyodide. If a pure Python package is not found in the Pyodide repository it will be loaded from PyPI.
This means that "installation" of the InfluxDB client is a case of running
import micropip
micropip.install("influxdb-client")
The "install" is within a page context, so that'll need running on every page load (althought the files will be fetched from the browser's cache on subsequent loads).
The Data
The next thing to do is to sort out access and work out what to query so that we can start to write a script.
I've written in the past about how I capture electricity usage into InfluxDB and that data ends up in InfluxCloud, so we'll try and query against that datasource.
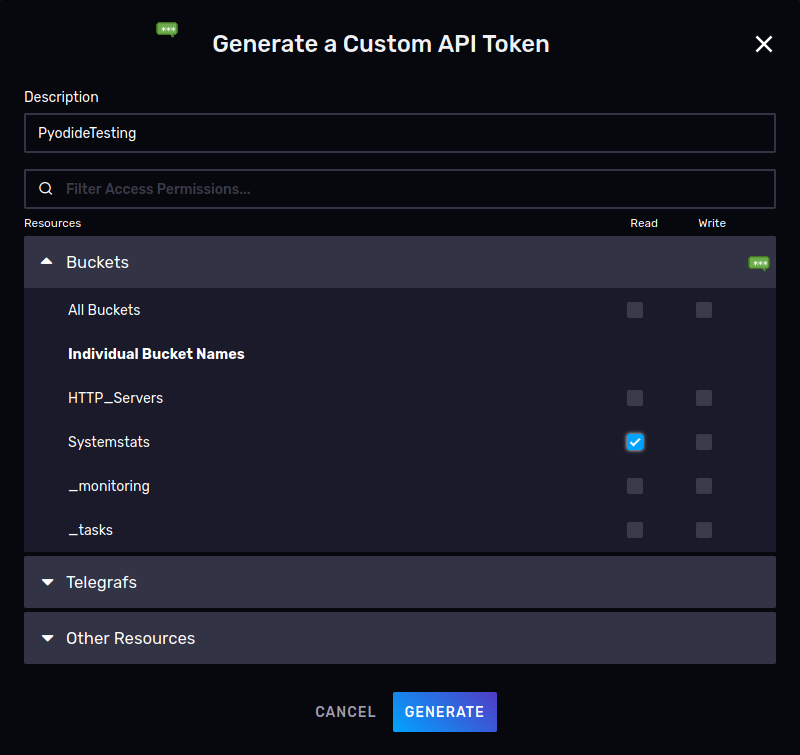
In InfluxCloud, I created a limited access API token, constraining it to only reading from the necessary bucket:
And quickly check that my Flux query returns data (don't want to blame the code if I've made a mistake)
from(bucket: "Systemstats")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "power_watts")
|> filter(fn: (r) => r["_field"] == "consumption")
|> aggregateWindow(every: 5m, fn: mean, createEmpty: false)
It does, so it's time to write a script.
Building and Running The Script
The InfluxDB client can be installed in Pyodide and we've created authentication credentials, so it should just be a case of writing a script to set up the client and run my query (man, we're storming through this project...)
import micropip
await micropip.install("influxdb-client")
# Start
import influxdb_client
bucket = "Systemstats"
org = "<my_org>"
token = "<my_token>"
url = "https://eu-central-1-1.aws.cloud2.influxdata.com/"
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
But, we get an error
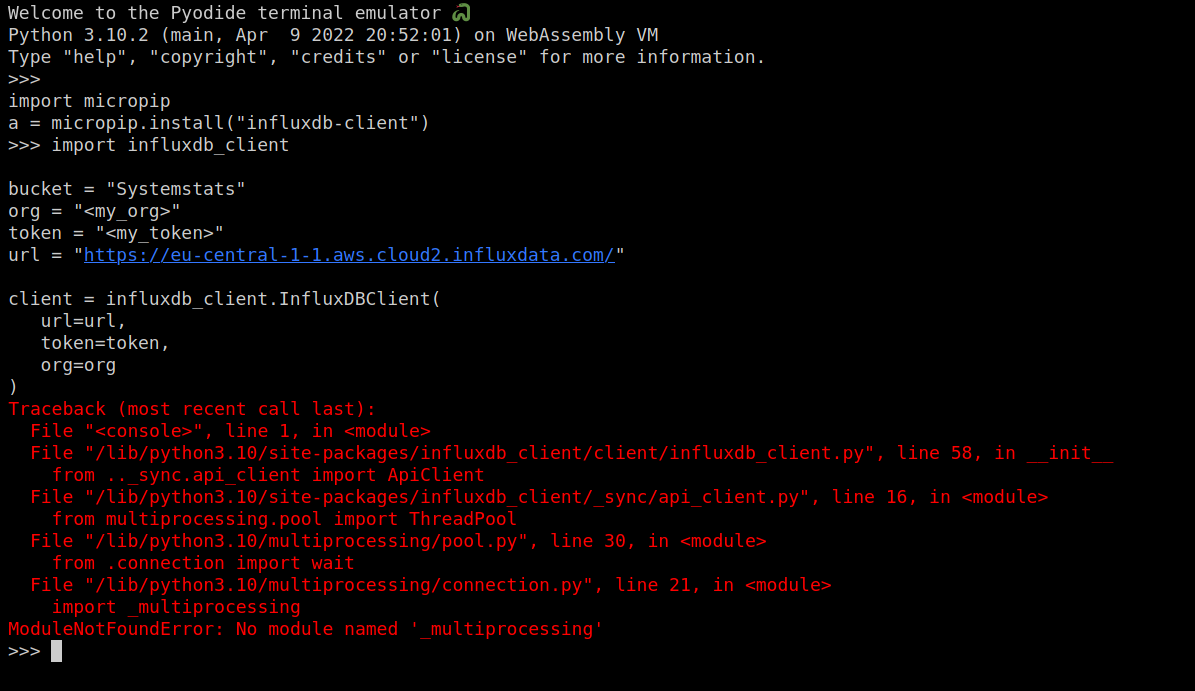
Pyodide doesn't currently support multiple processes (or threads).
We don't have to use multiprocesses within the client, but we do need the import to work.
To get around this, we can monkeypatch an object in as _multiprocessing to prevent this exception (if anything tries to use _multiprocessing though, it'll scream blue murder).
import micropip
await micropip.install("influxdb-client")
# Start
import influxdb_client
# Pyodide doesn't support multiprocessing, create a dummy object so imports
# don't throw exceptions
import sys
sys.modules['_multiprocessing'] = object
bucket = "Systemstats"
org = "<my_org>"
token = "<my_token>"
url = "https://eu-central-1-1.aws.cloud2.influxdata.com/"
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
We get a different error this time
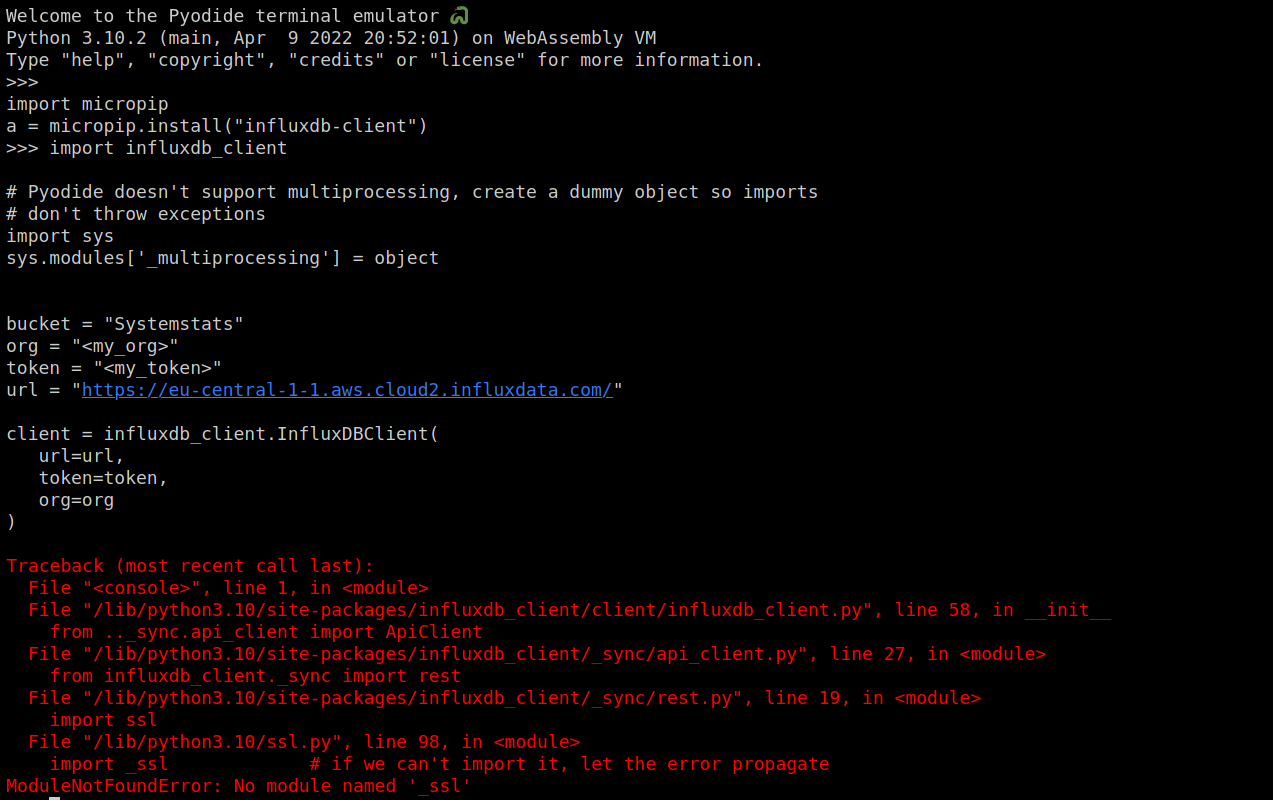
Apparently, Pyodide doesn't have the SSL module installed by default (weird). So we'll install that with micropip too.
This time, we're able to write more of the script before running into trouble
import micropip
await micropip.install("influxdb-client")
await micropip.install("ssl")
# Start
import influxdb_client
# Pyodide doesn't support multiprocessing, create a dummy object so imports
# don't throw exceptions
import sys
sys.modules['_multiprocessing'] = object
bucket = "Systemstats"
org = "<my_org>"
token = "<my_token>"
url = "https://eu-central-1-1.aws.cloud2.influxdata.com/"
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
query_api = client.query_api()
query = """
from(bucket: "Systemstats")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "power_watts")
|> filter(fn: (r) => r["_field"] == "consumption")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
"""
result = query_api.query(org=org, query=query)
Inevitably, though, trouble finds us
![OSError: [Errno 50] Protocol not available](../../../images/BlogItems/pyodide_influxdb_client/urllib.png)
urllib3 is pretty unhappy:
Traceback (most recent call last):
File "/lib/python3.10/site-packages/urllib3/connection.py", line 174, in _new_conn
conn = connection.create_connection(
File "/lib/python3.10/site-packages/urllib3/util/connection.py", line 95, in create_connection
raise err
File "/lib/python3.10/site-packages/urllib3/util/connection.py", line 79, in create_connection
_set_socket_options(sock, socket_options)
File "/lib/python3.10/site-packages/urllib3/util/connection.py", line 105, in _set_socket_options
sock.setsockopt(*opt)
OSError: [Errno 50] Protocol not available
A quick doublecheck shows that we've not made a mistake in our url variable (it is a URL, and we are passing the right variable in).
So, what gives?
[Errno 50] Protocol Not Available
The issue is actually much more severe than I first thought
Networking in Python does not work, since it relies on low-level networking primitives (socket) that aren't allowed in the browser sandbox.
So, although urllib3 is present in Pyodide, it can't actually connect to anything.
That's a pretty big problem given the aim of this exercise is to connect to a remote service. It's also a pretty fundamental error in my choice of experimental project. As a small consolation, this does explain the lack of ssl module.
Monkeypatching the client
I wanted to stop but my brain kept turning the issue over until I gave in and returned to the computer.
The plan is to try and monkeypatch the InfluxDB Python Client so that requests would pass via javascript rather than trying to use urllib3.
Rules
I set myself a few arbitrary rules
- Function arguments should not be changed (i.e. the query should still be run with
query_api.query(org=org, query=query)) - Return values should not be changed
- Monkeypatching only, no creating inheriting classes
The aim is to patch the client (however badly), not to create a reimplementation of it. If the way you interact with the functions or response changes then it's starting to lean toward reimplementation.
HTTP Handler
Pyodide provides a few methods for sending HTTP requests:
The open_url functions are pretty basic: they take a URL, fetch it and return the response - there's no apparent way to pass custom headers or change the request method. That's not a great fit, as we need to be able to set the authorization header in order to pass our authentication token and we need to POST our query.
pyodide.http.pyfetch looks much more promising
async http.pyfetch(url: str, **kwargs) → pyodide.http.FetchResponse
The documentation notes that **kwargs can be any of the optional parameters used for Javascript's Fetch API.
Included in those parameters are
bodyheadersmethod
Which are exactly what we need.
Finding Tokens etc
To authenticate against InfluxDB Cloud we need to know the authentication token and the organisation name.
Those are passed into an earlier object:
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
query_api = client.query_api()
result = query_api.query(org=org, query=query)
The easy solution would be to pass them into query(), but that would involve changing the function's arguments (and so break Rule 1).
Instead, we need to try and find out how the query_api object finds these details. Within the REPL/console we can use Python's dir to examine an object's properties
>>> dir(query_api)
['__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__',
'__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__',
'__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_build_flux_ast',
'_create_query', '_get_query_options', '_influxdb_client', '_org_param', '_params_to_extern_ast',
'_parm_to_extern_ast', '_query_api', '_query_options', '_to_csv', '_to_data_frame_stream',
'_to_data_frame_stream_async', '_to_data_frame_stream_parser', '_to_data_frames',
'_to_flux_record_stream', '_to_flux_record_stream_async', '_to_flux_record_stream_parser',
'_to_tables', '_to_tables_async', '_to_tables_parser', 'default_dialect', 'query', 'query_csv',
'query_data_frame', 'query_data_frame_stream', 'query_raw', 'query_stream']
Of those, _influxdb_client seems like it's most likely to hold credentials, so we dir that
>>> dir(query_api._influxdb_client)
['__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__',
'__exit__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__',
'__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'__weakref__', '_from_config_file', '_from_env_properties', '_version', 'api_client',
'auth_header_name', 'auth_header_value', 'authorizations_api', 'buckets_api', 'close',
'conf', 'default_tags', 'delete_api', 'from_config_file', 'from_env_properties', 'health',
'invocable_scripts_api', 'labels_api', 'org', 'organizations_api', 'ping', 'profilers',
'query_api', 'ready', 'retries', 'tasks_api', 'token', 'url', 'users_api', 'version',
'write_api']
Some of those look interesting
>>> query_api._influxdb_client.auth_header_value
'Token <my_token>'
>>> query_api._influxdb_client.token
'<my_token>'
>>> query_api._influxdb_client.url
'https://eu-central-1-1.aws.cloud2.influxdata.com/'
>>> query_api._influxdb_client.org
'<my_org>'
We now know how to access
- Org
- Auth Token
- Url
So we know where to send requests, and how to authenticate those requests.
Building a function
Now that we know how to access the variables we need, and what function to call to make a HTTP request, we need to jerry-rig the client to implement this.
We're going to define a new function and then overload that on top of one of the client's existing functions.
The function that we replace needs to meet two requirements
- It needs to be in our call chain (the closer to a direct call the better as we're less likely to break something else)
- It should be as simple as possible (minimises the chance of a future client update breaking our patching)
We're calling query() directly and it's a pretty basic function, so we'll start by trying to overload that.
For now, all we want is to place the request and return the result object (to prove that we definitely can generate a request and receive data back this way).
We define a new function accepting the same arguuments.
# Define our override
async def new_query(self, query: str, org=None, params: dict = None):
# Define custom headers
headers = {
"Authorization" : "Token " + self._influxdb_client.token,
"content-type" : "application/vnd.flux"
}
# Build the URL
url = self._influxdb_client.url + "api/v2/query?org=" + self._influxdb_client.org
# Trigger the fetch
a = await pyodide.http.pyfetch(url=url,
method="POST",
headers=headers,
body=query
)
return a
And then we overload this function into the query_api object and run our query
query_api.query = new_query
r = await query_api.query(query_api,q)
The request works and Developer Tools shows that we received a CSV back.
You might have noticed that there is a slight change in invocation: pyfetch is an asynchronous function, so we now have to include await in our call to query(). This meets the letter of Rule 1 (we didn't change the params), but it's arguable whether it's really in the spirit of it.
But, I'm going to let it pass.
Now that we've got working requests, we need to address the response object.
Our overloaded function currently returns an object of type pyodide.http.FetchResponse.
We could easily parse the CSV response body with csv.reader(), but that would break Rule 2: we need to return the same type as the vanilla version does.
So the next step is to amend our function to return the correct type (List['FluxTable'])
Processing the Response
The client translates the CSV to Flux tables by calling _to_tables which passes the data onwards into a FluxCsvParser object.
In an ideal world, we'd pass our response into _to_tables() and let the core code do all of the work.
However, we can't do that: our response is of a incorrect type, and the class quite reasonably requires one of two types
"""
Initialize defaults.
:param response: HTTP response from a HTTP client.
Acceptable types: `urllib3.response.HTTPResponse`, `aiohttp.client_reqrep.ClientResponse`.
"""
We can't easily transform our response into either of those, so instead need to look at how _to_tables() and FluxCsvParser process the object so that we can try to code around the requirement.
The relevant part of the vanilla call chain goes
query()_to_tables()-
_to_tables_parser()(returns an instance ofFluxCsvParser) FluxCsvParser.generator()FluxCsvParser._parse_flux_response()FluxCsvParser._parse_flux_response_row()
If called directly with our response object, an exception occurs because the method _parse_flux_response() will try and treat the response as a readable object.
So, we need to monkeypatch a couple more functions in to override where the relevant methods of FluxCsvParser get their input data from:
# This version is amended to
# - take a CSV
# - take a reference to the parser object
def generator(self, csv, _parser):
for val in self._parse_flux_response(self, csv, _parser):
yield val
# Amendments
#
# - Takes CSV string as input
# - Takes reference to parser
# - Reads CSV
#
def _parse_flux_response(self, csv_str, _parser):
metadata = _FluxCsvParserMetadata()
# String->IO object for CSV reader's sake
f = StringIO(csv_str)
rows = csv.reader(f)
for row in rows:
for val in _parser._parse_flux_response_row(metadata, row):
yield val
We can now update our query function to call these, essentially reproducing what _to_tables() does but calling our own functions.
async def new_query(self, query: str, org=None, params: dict = None):
# We'll come back to this
#q = self._create_query(query, self.default_dialect, params)
#print(q)
headers = {
"Authorization" : "Token " + self._influxdb_client.token,
"content-type" : "application/vnd.flux"
}
url = self._influxdb_client.url + "api/v2/query?org=" + self._influxdb_client.org
a = await pyodide.http.pyfetch(url=url,
method="POST",
headers=headers,
body=query
)
response = await a.string()
# The client would call _parser.generator here, but that calls _parse_flux_response() which'll treat
# us as a readable object, so we implement around it
_parser = self._to_tables_parser(response, self._get_query_options(), FluxResponseMetadataMode.only_names)
list(self.generator(self, response, _parser))
return _parser.table_list()
Because we're passing a reference to the parser into the Flux overloads, we can overload into query_api rather than figuring out the attribute path to put it into the parser (pure laziness on my part).
This makes our call chain
-
query()(overload) -
_to_tables_parser()(returns an instance ofFluxCsvParser) -
generator()(overload) -
_parse_flux_response()(overload) FluxCsvParser._parse_flux_response_row()
Our overload section now look like this
query_api.query = new_query
query_api.generator = generator
query_api._parse_flux_response = _parse_flux_response
With this change, our query() call returns the correct type, meaning that we can use a code snippet copied directly from the client documentation to interact with the result object
results = []
for table in result:
for record in table.records:
results.append((record.get_field(), record.get_value()))
print(results)
[('consumption', '73.5'), ('consumption', '75'), ('consumption', '73.6'),
('consumption', '71.4'), ('consumption', '71.2'), ('consumption', '74.2'),
('consumption', '71.4'), ('consumption', '71.2'), ('consumption', '73.4'),
('consumption', '71.6'), ('consumption', '71.4'), ('consumption', '72'),
('consumption', '72.33333333333333'), ('consumption', '0'), ('consumption', '0'),
('consumption', '0'), ('consumption', '0'), ('consumption', '0'),
('consumption', '0'), ('consumption', '0'), ('consumption', '0'),
('consumption', '0'), ('consumption', '0'), ('consumption', '0'),
('consumption', '0'), ('consumption', '0'), ('consumption', '604.8461538461538'),
('consumption', '604.6'), ('consumption', '611.04'), ('consumption', '634.28'),
('consumption', '730.0833333333334'), ('consumption', '760.96'),
('consumption', '756'), ('consumption', '638.52'), ('consumption', '649.04'),
('consumption', '644.28'), ('consumption', '724.8'), ('consumption', '722.2'),
('consumption', '686.6666666666666')]
Full Version
We can now put that all together to create something which should reliably work in the Pyodide REPL.
If you've got an InfluxDB Cloud account, or InfluxDB set up somewhere, you should be able to change the variables at the top of this script and paste it into the Pyodide REPL to get query results.
Whitespace has been minimised in functions to prevent the REPL complaining about loss of indent on empty lines.
# Creds etc
bucket = "Systemstats"
org = "<my_org>"
token = "<my_token>"
url = "https://eu-central-1-1.aws.cloud2.influxdata.com/"
query = """
from(bucket: "Systemstats")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "power_watts")
|> filter(fn: (r) => r["_field"] == "consumption")
|> aggregateWindow(every: 15m, fn: mean, createEmpty: false)
"""
import pyodide
import micropip
a = await micropip.install("influxdb-client")
a = await micropip.install("ssl")
del(a)
import influxdb_client
from io import StringIO
import csv
# Pyodide doesn't support multiprocessing, create a dummy object so imports
# don't throw exceptions
import sys
sys.modules['_multiprocessing'] = object
# Get bits from the Influx DB client
from influxdb_client.client.flux_csv_parser import FluxResponseMetadataMode, FluxCsvParser, FluxSerializationMode, _FluxCsvParserMetadata
# We're going to overlay some queries into the class
async def new_query(self, query: str, org=None, params: dict = None):
# Build headers
headers = {
"Authorization" : "Token " + self._influxdb_client.token,
"content-type" : "application/vnd.flux"
}
url = self._influxdb_client.url + "api/v2/query?org=" + self._influxdb_client.org
a = await pyodide.http.pyfetch(url=url,
method="POST",
headers=headers,
body=query
)
response = await a.string()
# The client would call _parser.generator here, but that calls _parse_flux_response() which'll treat
# us as a readable object, so we implement around itt
_parser = self._to_tables_parser(response, self._get_query_options(), FluxResponseMetadataMode.only_names)
list(self.generator(self, response, _parser))
return _parser.table_list()
# Replacement for
# https://github.com/influxdata/influxdb-client-python/blob/[5168a04](/commits/jira-projects/MISC/5168a04983e3b70a9451fa3629fd54db08b91ecd.html)/influxdb_client/client/flux_csv_parser.py#L105
def generator(self, csv, _parser):
for val in self._parse_flux_response(self, csv, _parser):
yield val
# Replaces line 115 in the same file
def _parse_flux_response(self, csv_str, _parser):
metadata = _FluxCsvParserMetadata()
f = StringIO(csv_str)
rows = csv.reader(f)
for row in rows:
for val in _parser._parse_flux_response_row(metadata, row):
print(val)
yield val
# Set up the client
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
query_api = client.query_api()
# Overlay our functions into the object
query_api.query = new_query
query_api.generator = generator
query_api._parse_flux_response = _parse_flux_response
# Run the query
r = await query_api.query(query_api,query)
# Iterate through the result object
results = []
for table in r:
for record in table.records:
results.append((record.get_field(), record.get_value()))
print(results)
Pyscript version
I started this journey having found out about PyScript so it'd be remiss of me not to take the script and work it into a PyScript.
Rather than pasting into a REPL, we're creating a HTML page that'll contain and execute our script.
Within <head> we include a copy of Pyscript
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
We no longer need to use micropip: there's a custom tag provided by pyscript to list our dependencies in
<py-env>
- ssl
- influxdb_client
</py-env>
As we're building a HTML page anyway, we probably also want to give the user input elements so that they can provide connection information and define the query
<h3>Config</h3>
Org: <input type="password" id="org"><br />
Token: <input type="password" id="token"><br />
Url: <input type="text" id="url" value="https://eu-central-1-1.aws.cloud2.influxdata.com/"><br />
<h3>Query</h3>
<textarea id="query">
from(bucket: "Systemstats")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "power_watts")
|> filter(fn: (r) => r["_field"] == "consumption")
|> aggregateWindow(every: 15m, fn: mean, createEmpty: false)
</textarea>
<button id="submit">Run</button>
This means we'll have to have our script interact with the DOM to collect those values, pyscript provides functions to allow us to do exactly that
org = Element("org").element.value
token = Element("token").element.value
url = Element("url").element.value
query = Element("query").element.value
We also need to figure out how to bind a click event that triggers our Python script, so that it can be run whenever the user clicks the Run button.
It turns out it's quite easy - we just need pyodide's create_proxy
def start_loop(event):
# Trigger the async loop
Element("submit").element.innerHTML = "running"
loop = asyncio.get_event_loop()
task = loop.create_task(main())
loop.run_until_complete(task)
# Enable the button
submit = document.getElementById("submit")
submit.addEventListener("click", pyodide.create_proxy(start_loop))
We're building an interactive experience, so let's have the script turn FluxTables into HTML tables
def tableise(results):
# Take FluxTable and print a HTML table
id = 0
for table in results:
records = []
cols = [x.label for x in table.columns]
for record in table.records:
r = []
for column in table.columns:
# Fetch each of the columns
r.append(record[column.label])
records.append(r)
insert_output_table(table.get_group_key(), cols, records, id)
id += 1
def insert_output_table(group_key, cols, records, id):
# Construct and insert the HTML table
d = document.createElement('div')
s = document.createElement('span')
s.innerHTML = f"Key: {group_key}"
d.appendChild(s)
t = document.createElement("table")
t.className = "sortable"
t.id = f"tbl{id}"
hr = document.createElement("tr")
for column in cols:
th = document.createElement("th")
th.innerHTML = column
hr.appendChild(th)
t.appendChild(hr)
print("Doing rows " + str(len(records)))
# Now do the data-rows
for record in records:
tr = document.createElement("tr")
for col in record:
td = document.createElement("td")
td.innerHTML = col
tr.appendChild(td)
t.appendChild(tr)
# Append the table to the div
d.appendChild(t)
# Push it all into the page
Element("output").element.appendChild(d)
Put it all together inside <py-script> tags and we're ready to run our query
No-one is ever going to give me an award for UI design, but the code works.
There's a copy of the full page at https://projectsstatic.bentasker.co.uk/MISC/MISC.2/, it should be possible to use it with any InfluxDB instance that has the v2 API active (you'll need to wait for the button to say Run - pyscript seems to load about 20MB of dependencies).
Caveats
Although we've not run into them in this experiment, it's worth noting some of the caveats affecting external HTTP access via the javascript layer
- CORS is enforced - if the server you're connecting to is on a different domain and doesn't return CORS headers, your requests will fail
- There are ports you won't be able to connect to: most browsers block access to ports are considered unsafe (Chrome returns
ERR_UNSAFE_PORTfor this) - you can see a good explanation of why this is here - If your code is running on a HTTPS site, the browser will prevent you connecting out to plain HTTP services
Conclusion
As I said at the beginning, I don't really have a cogent use-case for doing this, it was just a puzzle to solve.
The thing about fiddling with code, though, is that it's never pointless: most people learn best by doing, and sometimes the best way to learn unexpected things is to set yourself an odd and seemingly pointless puzzle to solve.
Although I don't currently have a need for it, there are use-cases for Pyodide and Pyscript.
In particular, if you've got an existing application/client written in Python, they provide a way to make it available to users via browser rather than having to reimplement in Javascript.
Clearly there are some potential headaches to watch out for though.
That urllib3 (and by extension, requests) can't work in Pyodide makes logical sense now that I'm aware of it, but the thought clearly hadn't occurred to me at the start of this (otherwise I'd probably have gone for a different experiment). Similarly, anything which uses multi-threading or multi-process is going to run into trouble.
I've found that startup is a little slow for Pyscript (in particular) as it has to pull in a bunch of dependencies, but once that's done, actual execution of the script really is pretty snappy.
Despite the headaches, it really is pretty cool to be able to run Python in-browser.