Adding WebMention Support to Nikola

For those who aren't familiar, WebMention is a W3 standard for conversations and interactions across sites/services. Webmentions are used by IndieWeb authors to help link mentions or replies back to the content that they relate to.
Some readers might remember the term "pingback": an XMLRPC call used (particularly on Wordpress sites) to let an author know you'd mentioned their content. WebMentions are basically the modern version of that.
Recently, I was reading a post by Terence Eden discussing the ethics of syndicating comments using WebMentions and found myself a little undecided on the question that Terence poses, at least as it applies to extracting comments from silos like Twitter (more detail on that here).
In considering the question, though, it did occur to me that sending WebMentions is always ethical: by exposing and advertising a WebMention endpoint, the author has signalled their willingness (and even, desire) to receive WebMentions.
So, I decided I wanted to look at adding WebMention support to my site, which is managed using the Nikola Static Site Generator (SSG).
Sending and receiving WebMentions with a something like a Wordpress site is fairly straightforward, just install a plugin like this one and everything is done for you.
With a SSG, sending isn't much harder (we still just need a plugin), but receiving directly isn't possible because there simply isn't a dynamic stack to receive and process incoming mentions.
In this post, I'll detail the process I used to set my Nikola based site up to send and receive/display WebMentions from around the web. I've used a similar process for some of my non-Nikola static sites too.
Contents
How WebMentions work
To begin with, it's probably worth having a high-level understanding of how WebMentions are sent in order to be able to properly assess whether there's any additional risk involved in enabling them.
If you don't care about this bit, jump down to Sending Webmentions.
The following explanation assumes that a post is published at https://some.where/page.html linking to https://www.bentasker.co.uk/.
Sending end
The plugin on our site will
- Place a HTTP
HEADrequest againsthttps://www.bentasker.co.uk/ - Look for a
linkHTTP response header which contains eitherrel=webmentionorrel=webmention.org - If a header isn't found it'll place a
GETrequest againsthttps://www.bentasker.co.uk/ - It'll check that the response is HTML and then look for a
linktag withrel=webmention(orrel=webmention.org) - If neither is found, processing stops (we can't send a webmention)
- Otherwise, we now have the URL of the webmention endpoint for
www.bentasker.co.uk
The plugin will then send the webmention by placing a POST request to the webmention endpoint, sending two form fields: source and target
source=https://some.where/page.html&target=https://www.bentasker.co.uk/
Sending is now complete, but there are some follow up actions by the receiving end
Receiving end
On receipt of the webmention, the www.bentasker.co.uk Webmention endpoint will do some processing of it's own
- It'll check that it accepts Webmentions for
https://www.bentasker.co.uk/ - It'll check that the sender (
https://some.where) is not blocklisted - It'll place a HTTP
GETrequest forhttps://some.where/page.htmland validate that there is in fact a link out tohttps://www.bentasker.co.uk/ - It'll record the mention in it's database for later retreival/display
Some implementations will also process the page to look for microformats such as h-entry so that it can record some context about the mention (is it a reply, who was the author etc). Conveniently, some of Nikola's templates already have h-entry notations in them.
Overview
So, to summarise, when you send a WebMention a couple of actions happen on your system
- You'll request the URL you linked to
- You may parse the page you linked to
- You'll place a request to the webmention endpoint
- You'll receive a request from the webmention endpoint
What little risk does exist primarily lies in Step 2: the plugin is going to fetch and parse an arbitrary page. This is mitigated by the fact that you need to have linked to that page (and hopefully won't be linking to anything too dodgy from within your content), but there is still a very small element of risk there.
The receiver's side carries a little more risk (because they're responding to the actions of others), but again it should normally be relatively minor.
Sending WebMentions
Now that we we understand what we're going to be implementing, it's time to look at setting Nikola up to send webmentions.
The Plugin
In the intro to this post, I said that sending from Nikola isn't too hard, because we "just need a plugin".
There is a minor issue with this: At time of writing, the list of Nikola Plugins doesn't include anything which provides WebMention (or even pingback) support.
Not to be defeated at the first hurdle, I wrote one: WebMention plugin for Nikola.
Plugin Install
Update: my Pull request has now been merged, and the plugin is in Nikola's plugin directory, so I've removed the manual install steps from this section.
The Webmention plugin fires when nikola deploy completes and will process any post or page with a Date more recent than the last recorded deploy. This means that, if you've never run nikola deploy, on the first run it'll work through all of your pages and posts, which probably isn't desirable.
The first thing to do, then, is to trigger a deploy so that the plugin only fires for newly created content.
Note: you don't need to have configured any DEPLOY_COMMANDS in Nikola's config to do this, it'll simply update the internal state record to record the time of the deploy.
nikola deploy
Then, tell Nikola to fetch and install the plugin
nikola plugin -i webmentions
That's it, the plugin's installed and doesn't require any special configuration.
Using The Plugin
There's no requirement to use any special markup or format within your posts, just link out to wherever you're going to link, using whatever format suits you:
Lorem ipsum dolor sit amet, consectetur adipiscing elit,
sed do eiusmod tempor incididunt ut labore et dolore
[magna aliqua](https://www.bentasker.co.uk/).
Build your site as you normally would
nikola build
Once that has completed, trigger deploy
nikola deploy
If all goes well, you'll simply see output like the following
Scanning posts........done!
[2022-12-10 00:08:11] INFO: deploy: => preset 'default'
[2022-12-10 00:08:11] INFO: deploy: Successful deployment
[2022-12-10 00:08:11] INFO: webmentions: Processing https://www.bentasker.co.uk/pages/licenses/mit-license.html
If the plugin encounters a serious error, it'll output details. Otherwise, no news is good news.
More Advanced Markup
Most mentions will derive from simple links, like the one used in the example above.
However, you might occasionally want to provide additional context for certain mentions, and can do so by using some slightly more advanced markup in your post.
For example, when quoting a part of someone else's post, you can include h-entry microformat annotations to indicate what you're replying to
<div class="h-entry">
<div class="u-in-reply-to h-cite">
<blockquote cite="https://foo.bar.invalid" class="p-content">
It's unhackable!
</blockquote>
</div>
<p class="e-content">O Rly?</p>
</div>
This indicates that we're replying O Rly? to the statement It's unhackable! originally made on https://foo.bar.invalid.
It's also possible to go a bit further. Perhaps https://foo.bar.invalid has multiple authors (or, maybe our page does) and we want to show who we're replying to.
We can mark all (or some) of that up too
<div class="h-entry">
<div class="u-in-reply-to h-cite">
<!-- Note the original author -->
<p class="p-author h-card">Alice</p>
<!-- Quote the segment we're responding to -->
<blockquote cite="https://foo.bar.invalid" class="p-content">It's unhackable!</blockquote>
<!-- Link with that one -->
<a class="u-url" href="https://foo.bar.invalid">
<time class="dt-published">2022-12-09</time></a>
</div>
<!-- Who we are -->
<p class="p-author h-card">Bob</p>
<!-- Our response -->
<p class="e-content">O Rly?</p>
</div>
Assuming that https://foo.bar.invalid supports WebMentions and supports h-entry, it would record this as a reply-to action, showing that Bob replied O Rly? to Alice's statement that It's unhackable! on https://foo.bar.invalid.
The different Mention types available for use can be seen here, but include
u-in-reply-top-rsvpu-like-ofu-repost-ofu-bookmark-of
Useful Notes
There are a few things that might be useful to know about the plugin:
- It's a SignalHandler Plugin.
- Nikola emits the
deployedevent after all deployments have successfully completed, so if you have multiple deployment commands and one fails, webmentions won't be sent until the next successful run. - The plugin ignores posts/pages that are not published, so if the metadata includes
status: draftwebmentions will not be sent for links in that page (but will when it's later published) - Nikola's deployments handler only considers posts/pages where the post's date is more recent than the date of the last deployment: if you want Webmentions sent after updating existing posts, remember to update the
Updateddate in the post's metadata - The plugin tracks state, if you edit an existing page, it won't resend webmentions for URLs that it's already seen
- The plugin is released under MIT License
To make the install process less cumbersome, I put a pull request in to have the plugin added to the Nikola plugins site.
Now that it's been merged, install is just be a case of
nikola plugin -i webmentions
There were some changes required to get it merged, those have been fed back into my repo, and v0.1 has been tagged and released.
Relevant links:
- https://github.com/bentasker/nikola_ssg_webmentions
- https://github.com/getnikola/plugins/tree/master/v8/webmentions
- https://plugins.getnikola.com/v8/webmentions/
Receiving WebMentions
We probably also want to be able to receive WebMentions so that we can see when others link to our posts.
For a dynamic site, this would be relatively straightforward, you'd just need a plugin capable of receiving requests and completing the flow.
A static HTML website clearly cannot do that on it's own, so we're going to have the fantastic WebMention.io handle this for us.
webmention.io Setup
For the purposes of this document, we'll use the hosted service. However, webmention.io is open source and you can run your own instance instead if you'd prefer.
Whichever you use, once you're up and running, consider sending webmention.io's maintainer Aaron Parecki a donation to say thanks (there are Venmo, Paypal and Cashapp links at the bottom of his profile).
The service uses IndieLogin for authentication, so when you land on the page you'll see a sign-in box like this
There's a little bit of inital setup required before we'll be able to login.
The way that IndieLogin works is described here, but it basically relies on your site providing (or pointing to) a trusted authentication provider. Because we're a static site, we haven't got a built in IndieAuth provider and so need to instead add a link to another provider
You can follow the instructions for your chosen authentication provider.
I opted to use GitHub, which meant adding the following at the bottom of my site template
<a href="https://github.com/bentasker" style="display: none" rel="me authn">github.com/bentasker</a>
My Github profile already linked back to my site, so I didn't need to change anything there.
Once you've updated your template to contain the relevant tag, build the site
nikola build
nikola deploy
Go back to webmention.io and enter your site address into sign-in page, you should then be asked to authenticate using your chosen method.
Once logged in, the Setup page will be displayed, providing details of the tags that you need to add to your page in order to advertise the Webmention endpoint
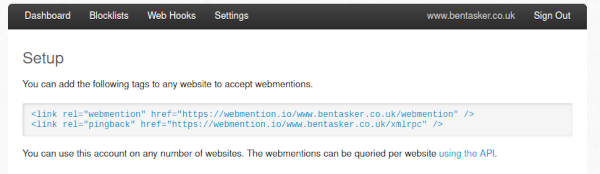
These can be added to your site's template, however, the Webmention spec also supports advertising Webmention endpoint information via HTTP response headers.
Advertising via response header is generally more efficient, because you don't need to send the entire page to the requesting client.
The Wordpress WebMention plugin sends a HEAD first, so there are some bandwidth and resource savings which can be unlocked by using headers (if a Wordpress site links to you, there won't be any need to send their plugin the full page because they can get what they need from your headers).
If you're concerned about maximising compatability, you can of course use both headers and tags (although standards compliant implementations should all support using the Link header).
To add the headers in Nginx, we insert the following into the relevant server/location block (remember to correct the path to represent your endpoint)
add_header Link '<https://webmention.io/www.bentasker.co.uk/webmention>; rel="webmention"';
add_header X-Pingback 'https://webmention.io/www.bentasker.co.uk/xmlrpc';
Reload Nginx's configuration
systemctl reload nginx
and the headers should start to be sent.
You can verify this with a command like
curl -X HEAD -s -v -o/dev/null https://www.bentasker.co.uk 2>&1 | grep -i link
Which should result in your configured header being output.
Collecting Mentions from Siloed Sources
Social networks such as Twitter work very hard to try and drive "engagement" in order to keep their user's eyes on their ads. It's really not in their interest to encourage users to look elsewhere.
Unsurprisingly, then, they don't send WebMentions. This means that it's up to us to locate and collect mentions from within those services.
Jumping back to the introduction to this post, this is where I feel a little conflicted about the ethical posture of collecting and syndicating mentions.
My initial argument had been that users published their comments/tweets publicly and so, in principle, it's really not much different to a screenshot being taken. Rightly or wrongly, that's a fairly common occurrence on social media, and so should reasonably be expected by most users.
However, I do find it a little hard to escape the feeling that it's also not entirely dissimilar to people searching for mentions of themselves. That's a behaviour most visibily practiced by users with some fairly problematic tendencies, often jumping uninvited into threads to troll, argue and abuse.
Does the behaviour's association matter, though, if you're not jumping into other people's conversations? There's no real way to say whether problematic behaviour even represents the majority of the use-case: We don't see many examples of non-problematic uses because, by definition, they are unintrusive.
Getting back on topic though, if you do want to collect mentions from various social media sources, you'll need a bridging service like Bridgy.
It's worth noting that on most networks, bridgy can only collect interactions made in response/reply to a post you made on that social network, or those from users who have themselves connected bridgy to their accounts.
For me, that's perfect and addresses the ethical concerns I've described above: interactions are only collected from users who are either interacting with one of my tweets/posts or have actively consented by connecting brid.gy to their account.
It's also worth noting that brid.gy cannot collect from Facebook or Instagram unless you run their browser extension. Whilst cumbersome, this is actually an improvement on the previous state, as Facebook's Cambridge Analytica changes seriously impacted Brid.gy.
This has little impact on me, as I don't use Facebook.
Retrieving and Displaying Mentions
We've now implemented sending and (indirectly) receiving WebMentions.
What we've not done, however, is implement a way to actually display those mentions on our Nikola site.
It's certainly possible to build a Nikola plugin to retrieve and publish them (possibly using the static comments plugin to handle managing/publishing them), but mentions would only be updated when the site is rebuilt/deployed, which might not be very often.
The easiest way to retrieve mentions and ensure that they update regularly, is to use Javascript to call the webmention.io API.
Because parts of it are specific to my site, what follows is intended less as a "How To" and more as a "here's how I did it". If you're after a more generic solution, have a look at using something like webmention.js.
The first thing to do, is to retrieve mentions from the API.
The API itself is simple enough, we just need to place a GET to https://webmention.io/api/mentions.jf2?target=<our url> and we'll receive a JSON list of mentions, ordered most recent first.
We can use Javascript's fetch() API to achieve this
async function fetchComments(){
/*
Place a request to the API
then iterate over mentions, excluding unwanted
mention types
*/
var i, o, response, mentions, url;
var property_names = {
"mention-of" : " Linked To ",
"in-reply-to" : " Mentioned ",
"bookmark-of" : " Linked To ", // Reddit posts seem to get this
"repost-of": " Reblogged ",
}
// Not included
// like-of
// rsvp
// Calculate the API URL to call
url = "https://webmention.io/api/mentions.jf2?target=" + window.location.href;
response = await fetch(url);
response.json()
.then(mentions => {
// Iterate over returned mentions
for (i=0; i<mentions.children.length; i++){
m = mentions.children[i];
o = {}
o.mtype = m["wm-property"];
o.id = m["wm-id"];
if ((window.blockedMentionIDS && window.blockedMentionIDs.includes(parseInt(o.id))) || ! property_names.hasOwnProperty(o.mtype)){
// Skip
continue;
}
o.action = property_names[o.mtype];
o.author = m.author.name;
o.authorurl = m.author.url;
o.url = m.url;
if (m.content && m.content.text){
o.textsnippet = m.content.text.slice(0, 120) + "...";
}
if (m.published){
o.published = m.published;
} else {
o.published = m["wm-received"];
}
insertComment(o);
}
});
}
The function iterates over returned mentions, skipping unwanted mention types (I don't see much benefit in displaying "likes", but YMMV) and any blocked IDs, before calling the function insertComment() against each.
So, we now need to define that function. It's quick and nasty, but builds a set of elements to inject into the DOM in order to display the mention
function insertComment(comment){
// This is where all the comments will live
commentsection = document.getElementById('commentwrap');
// Create a wrapper for the mention
wrap = document.createElement('div');
wrap.className = "commentline";
wrap.id = "mention-" + comment.id;
author = document.createElement('span');
author.className = "commentauthor";
author.innerText = comment.author; // Could also optionally link out to their profile
wrap.appendChild(author);
action = document.createElement('span');
action.className = "commentaction";
action.innerText = comment.action;
wrap.appendChild(action);
filler = document.createElement('span');
filler.className = "commentfiller";
filler.innerText = "this on ";
wrap.appendChild(filler);
// Parse the url to extract the domain
var url = new URL(comment.url);
domain = document.createElement('span');
domain.className = "commentdomain";
domainlink = document.createElement('a');
domainlink.href = comment.url;
domainlink.rel = "noopener nofollow";
domainlink.target = "_blank";
domainlink.innerText = url.hostname;
domain.appendChild(domainlink);
wrap.appendChild(domain);
if (comment.textsnippet && comment.textsnippet.length > 0){
mentiontext = document.createElement('span');
mentiontext.className = "mentionText";
mentiontext.innerText = comment.textsnippet;
wrap.appendChild(mentiontext);
}
// Process the date
sp = comment.published.split('T');
sp2 = sp[1].split(":");
ts = sp[0] + " " + sp2[0] + ":" + sp2[1];
// Add
datespan = document.createElement('span');
datespan.className = "commentdate";
datespan.innerText = ts;
wrap.appendChild(datespan);
// Push into the DOM
commentsection.insertBefore(wrap, commentsection.firstChild);
}
Note that content from the mention is added using .innerText and not .innerHTML. This is to ensure that people can't post/tweet HTML nastiness in order to have it embedded into the site.
Although adding a div called commentwrap and calling fetchComments() would now work, I prefer to err on the side of caution: having arbitrary comments from around the web automagically appear on your site really isn't the best of ideas. Instead, it's better to display a clickable placeholder so that mentions are only displayed if the user actively signals they want to see them.
I add the place holder with Javascript because the functionality it triggers itself relies on Javascript: there's no point cluttering the page up with a non-functioning placeholder for users who've disabled JS.
function addCommentDiv(){
var before = 'latestposts';
var ae = document.getElementById(before)
if (!ae){
// Can't find the latest posts module
return;
}
h3 = document.createElement('h3');
h3.innerText = "Mentions";
var d = document.createElement('div');
d.id = "commentwrap";
d.innerText = "Click to display comments"
d.addEventListener('click', function(e) {
// Prevent multiple clicks
if (window.commentsDisplayed != 1){
e.target.innerHTML = '';
fetchComments();
window.commentsDisplayed = 1;
}
});
// Look up the div we want to insert before
// mine has an ID of latestposts
ae.parentNode.insertBefore(h3, ae);
ae.parentNode.insertBefore(d, ae);
}
Finally, we add a little bit of CSS to style the new elements
#commentwrap {
border: 1px solid;
padding: 20px;
}
.commentline {
border-bottom: 1px solid;
max-width: 95%;
margin: auto;
padding-bottom: 5px;
padding-top: 10px;
}
.commentdate {
display: block;
font-style: italic;
opacity: 0.8;
}
.mentionText {
display: block;
padding-left: 20px;
padding-top: 10px;
padding-bottom: 10px;
}
This provides for a nice simple interface

The mention links out to the original reference, and where available, includes the first 120 characters of what was said (120 is just the number I chose, you can adjust the slice() call in fetchComments() if you want more/less).
Mention Moderation
As noted above, there are some risks involved in embedding comments from around the web onto your site. People are shit, so there is always a possibility of problematic mentions.
Once aware of an issue, there are two ways in which you can deal with unwanted mentions.
The first is to go to https://webmention.io/settings/blocks, find and delete the relevant mentions (and/or block the domain if it's a regular source of issues).
Alternatively, the javascript snippets above also provide a means to block mentions by ID. If you right click on a mention and choose "Inspect" you should see the webmention ID in the element ID:
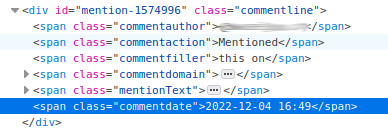
In this case, we can see it's 1574996 (I've blurred the author name because this mention isn't actually problematic at all, just one I picked to use as an example).
You need to take this ID and ensure that that ID exists in the javascript array window.blockedMentionIDS.
This can be achieved by embedding it into the relevant page (or your template)
<script type="text/javascript">
window.blockedMentionIDS = [1574996];
</script>
Alternatively, as I have, you can amend the calling code to fetch a file populated with blocked IDs:
function processBlockedMentions(xmlresponse){
// Try and fetch a list of blocked mention IDs
try {
window.blockedMentionIDs = JSON.parse(xmlresponse);
} catch (err) {
window.blockedMentionIDs = [];
}
}
function addCommentDiv(){
var before = 'latestposts';
var ae = document.getElementById(before)
if (!ae){
// Can't find the latest posts module
return;
}
h3 = document.createElement('h3');
h3.innerText = "Mentions";
var d = document.createElement('div');
d.id = "commentwrap";
d.innerText = "Click to display comments"
d.addEventListener('click', function(e) {
if (window.commentsDisplayed != 1){
e.target.innerHTML = '';
fetchComments();
window.commentsDisplayed = 1;
}
});
// Look up the div we want to insert before
// mine has an ID of latestposts
ae.parentNode.insertBefore(h3, ae);
ae.parentNode.insertBefore(d, ae);
fetchPage("/assets/blockedMentions.json", processBlockedMentions, function(){});
}
In the code above, fetchPage is the xmlhttp wrapper function defined in this snippet.
Within the Nikola directory structure, the blocklist file would be files/assets/blockedMentions.json and contains
[1574996]
With this defined, fetchComments() will skip the webmention with ID 1574996.
Improving Privacy and Performance
So far, the webmention retrieval implementation relies on the user's browser connecting directly to webmention.io.
Whilst they're probably not looking, this gives the operators of that service the ability to see who's visiting my site, and when, which really isn't in keeping with my efforts to maximise visitor privacy.
It's also inefficient: the user's browser needs to resolve and connect to an entirely different domain in order to retrieve the mentions.
To address this, I now pass those requests via a (caching) proxy: not only does it alleivate unnecessary load from webmention.io, but it helps to protect visitor's privacy by ensuring that they're no longer connecting directly to the service.
This proxy is implemented by adding the following location block to the site's nginx config
location ~ ^/get_webmentions/(.*)$ {
set $webmention webmention.io;
set $target $1;
resolver 1.1.1.1;
add_header x-loc $target;
proxy_set_header Host $webmention;
proxy_set_header User-Agent "webmention fetch";
proxy_http_version 1.1;
proxy_pass https://$webmention/api/mentions.jf2?target=https://$http_host/$target;
proxy_read_timeout 30s;
# Upstream sends no-cache, but we want the downstream CDN to cache for a short while
proxy_hide_header cache-control;
proxy_cache my-cache;
proxy_cache_lock on;
proxy_cache_valid 200 1h;
proxy_cache_key "$scheme$webmention-$target";
}
A simpler configuration is possible, but increases the possibility of the path being misused to place API calls for other domains.
The fetch() call in fetchComments() has been updated so that it places requests via the proxied path
url = "/get_webmentions/" + window.location.pathname;
response = await fetch(url);
Because I run a static site, I've configured my CDN to ignore query strings. This is why the page URL has been moved into the request path - otherwise the CDN will serve the same result for all pages.
As a result of the changes, all webmention retrievals now go via the cache, which also strips things like user-agent from upstream requests to webmention.io.
Conclusion
Sending WebMentions is a good thing to do: you're letting authors know that you found their content useful enough to link to (and everyone enjoys the dopamine hit that receiving such a notification creates).
Adding WebMention support to a Nikola site is relatively straightforward, though receiving and displaying is a bit more complex than sending.
The plugin that I've created will likely improve further over time: amongst other things, I'd like to add the ability to blocklist domains and make the state tracking more efficient. But, it's functional and does what I currently need.
Receiving and displaying webmentions is a more complex for a static site than for a dynamic content management system. However, services like webmention.io help simplify this to the point that the only real challenge is in deciding how you want to display the mentions.
My solution makes it possible to do some moderation of mentions if necessary, however, it's reactive moderation: you cannot take action against a mention until you become aware of it, which will usually be after it's already been displayed on your site.
It's certainly possible to build a solution which works the other way round: retrieving mentions into an offline store and then having you approve mentions before they are published.
In fact, the dynamic CMS world clearly already has this: Terence Eden alludes to following exactly this process in the blog post which set me on this path in the first place.
I may well look into building something more approval based at some point (in principle it could be a simple set of python scripts which ultimately write out comment files for static comment to consume), but wanted to be able to get up and running reasonably quickly (or more precisely, didn't want to have to think about what the UI and workflows for it would look like).
As a result of the changes, my site now sends WebMentions when I publish and pages can include some visibility of my content being mentioned around the web.
This post, incidentally, will also be the first real post since I enabled my WebMentions plugin: if there's a sudden slew of commits in the GitHub repo it means I missed something!