Creating A Log-Analysis System To Autodetect and Announce Mastodon Scraper Bot Activity

There's been a lot of talk on Mastodon about fediverse crawlers and scrapers recently, with one project after another popping up, running into concerns around consent and ultimately being withdrawn.
Most of these projects rely on scraping information that Mastodon makes public, whether that's data about activity on the instance or the toots of individual users.
Whilst these sort of projects are generally considered unwelcome in the fediverse, they are, unfortunately, just the tip of the ice-berg and it'll come as no surprise to many that there are many other scrapers quietly going about their work.
One theme that's common amongst fedisearch projects, is that they'll often be active for weeks before anyone becomes aware of them, with that awareness generally arising because the author announces their "product". As a result any measures that an admin might want to put in place are often much delayed.
A defensive model providing such a large window of opportunity really isn't workable, not only is there ample time for harm to be done, but if the developer never announces their scraper, general awareness of it may never even arise.
During one of the recent fedi-search kerfuffles, I decided that that gap in alerting was something that I wanted to try and address.
I'm no stranger to log analysis and similar techniques, so I set about the process of building an agent to automate the process of bot identification, with the aim of creating a system that would use behavioural scoring to identify bots in my mastodon logs and then toot details about the bot for other instance admins to use.
The aim of this post is to talk about the implementation that I've built, and how admins can make use of the information that it provides.
Contents
High Level Summary
Some of my posts have been a bit wordy lately and I don't expect that this one will be much different, so I thought I'd start with a high-level overview for those who don't really want to read a prolonged technical explanation.
What This Isn't
Let's start with what this system isn't:
It's not a panacea and it is explicitly not intended to provide an exhaustive list of every IP observed making scraper like requests.
What This Is
The system is designed to try and minimise the risk of false positives and alert about possible persistent threats, surfacing information in order to try and help instance administrators make informed decisions on what to block.
Essentially, the aim was to create a small osint resource to help admins look after their own instances.
What This Does
It's essentially a find-and-alert implementation. It watches the logs for my mastodon instance and assigns behavioural scores to each logline. If a client IP achieves a high enough score, for long enough, it's considered a scraper and will be passed onto an associated bot which will toot a summary.
Because of that time requirement, reports are not instant - a suspected bot needs to appear in more than 1 days logs. This helps to provide a level of certainty, whilst still raising awareness faster than would otherwise be the case.
This means that it's possible to have a reasonable level of confidence in the results, at the cost of a small delay in disclosure.
How Can I Use It?
The bot toots alerts from @scrapersnitch@mastodon.bentasker.co.uk.
To try to prevent and mitigate mistakes, toots are marked "Followers Only": if you want to receive them you'll need to follow the account. In order to help prevent the bot itself being treated as an apex point for targeting admins, the bot's social graph is hidden.
Additional OSINT about each reported IP is automatically published into https://botreceipts.bentasker.co.uk/, you should review and consider the information there before implementing a block.
The bot is likely to be extremely low-volume, although there are a number of scrapers active in the fediverse, new entrants are a relatively rare occurrence (even if not as rare as might be wanted).
Additional Caveats
As I've written before, IP blocks should only ever be one part of a solution.
There are more than a few scrapers (including some associated with some fairly problematic instances) crawling the fediverse using shared or ephemeral IPs, which cannot reliably be addressed with IP blocklists.
It's never going to be possible to catch everything, but relying on IP blocks leaves far more unblocked than should really be considered acceptable.
Whilst more advanced methods are obviously desirable, at the very least, a blocking solution should include support for blocking based on user-agent (allowing some additional low-hanging fruit to more easily be pruned out).
Lower Level Overview
Now for the fun stuff, if you're not looking for techo talk, jump down to "Other" below.
I've recently realised that I quite like making crappy markdown workflow diagrams, so let's start with one of those
|--------------------|
| Logs |
|--------------------|
1.|
|
V
|--------------------|
| Log Agent |
| (Request Scoring) |
|--------------------|
2.|
|
V
|--------------------|
| Time Series |
| Database |
|--------------------|
^ 4. |
| |
| |
SQL |
3.| V
|--------------------|
| Analysis Bot |
| Gen. Report |
|--------------------|
5.| 6. |
| |
V |
|----------| |
| Receipts | |
|----------| |
|
V
|--------------------|
| Mastodon |
|--------------------|
Request Scoring
The log-agent works on the same basis as the one that I described here, reading in and parsing access log lines in order to assign a behavioural score.
For obvious reasons, I don't want to go into too much detail on exactly what it looks for, but the score is calculated based on a range of criteria, including:
- Did my WAF object to it?
- How did Mastodon respond to it?
- Do the logged request headers look legitimate?
- How well does the request meet the expected profile of a legitimate client?
- Which path was accessed?
If a logline crosses the scoring threshold, it's written into the exceptions database, ready for further analysis.
Analysis Bot
The log-agent is quite a simple check, only really being capable of looking at each request in isolation. In practice, it's necessary to analyse behaviour across multiple requests, because users sometimes do things which look illegitimate too.
There's also little point in flagging ephemeral IPs: blocking an IP which will never be seen again is wasted effort and the noise of reports for those might lead to more consistent threats being missed.
Essentially, as all good alerting systems should, we want to ensure that every alert event counts in order to prevent complacency from creeping in to the human response.
To exclude the unwanted groups, the second stage of analysis applies some additional criteria
- Exclude any IPs which have already been tooted (so that we don't spam timelines)
- Only include scrapers that have been observed across multiple days
- Exclude IPs which have too few requests in the queried period
- Exclude any that fail to achieve a minimum average score
These requirements are implemented by the following SQL query
WITH "already_snitched" AS (
-- Get IPs that have already been reported
-- they'll be excluded later
SELECT DISTINCT
ip
FROM snitched
WHERE
time < now() + interval '1 minute'
),
"new_bots" AS (
-- Identify new IPs
SELECT DISTINCT
ip
FROM
(
-- Ensure the IP as been seen on multiple days
-- there's no point blocklisting something that's only been
-- seen once as it may be ephemeral
SELECT
ip,
sum("days") as "days_observed"
FROM
(
-- Break into day bins for the calculation above
SELECT
ip,
date_bin(interval '1 day', time, timestamp '1970-01-01T00:00:00Z') as day,
max(1) as "days"
FROM
mastodon_bots
WHERE
-- Exclude the stuff that's already been reported
ip NOT IN (SELECT ip FROM already_snitched)
AND time < now() + interval '1 minute'
GROUP by ip, day
)
GROUP by ip
)
-- Apply the minimum day count
WHERE "days_observed" > {min_days}
)
-- Retrieve from the bot log
SELECT
*
FROM
(
-- Get number of requests and average score
SELECT
count("behaviour_score") as reqs,
sum("behaviour_score")/count("behaviour_score") as "avg_score",
ip
FROM mastodon_bots
WHERE
-- Limit to the IPs selected by the previous statements
ip in (SELECT ip FROM "new_bots")
-- Limit to records seen in query_period
AND time > now() - interval '{query_period}'
GROUP BY ip
)
WHERE
-- Apply minimum number of requests and per-request score
reqs > {min_reqs}
AND "avg_score" > {min_score}
(The filter WHERE time < now() + interval '1 minute' is actually stored in a configuration variable, allowing the analysis to be configured to forget about a bot's activity after a set interval).
The score threshold applied by the analysis bot is significantly higher than that used by the log-agent. The log-agent tries to make data available for this query to use in it's analysis, but we need to achieve that higher threshold before considering automated public disclosure.
Having acquired a list of suspected bots, the system moves on to building reports.
Receipt Report Building
Although the bot's toots only contain limited information, the associated receipts files need to contain enough to be useful to admins when making a decision.
So, as well as collecting information about the types of exceptions seen, it also does some basic OSINT checks on the IP.
Checking for a reverse DNS record:
import dns.resolver
import dns.reversename
addrs = dns.reversename.from_address(ip)
try:
ipinfo['ptr'] = str(dns.resolver.resolve(addrs,"PTR")[0])
except dns.resolver.NXDOMAIN as e:
# No record
ipinfo['ptr'] = "None"
except:
ipinfo['ptr'] = "Query Errored"
Fetching information on the parent block from whois
from ipwhois import IPWhois
try:
obj = IPWhois(ip)
res=obj.lookup_whois()
ipinfo['ASN'] = res['asn']
except:
ipinfo['ASN'] = "Query Errored"
Checking whether the IP is that of a Tor exit node
import dns.resolver
import dns.reversename
try:
a = str(dns.resolver.resolve(f"{ip_rev}.dnsel.torproject.org","A")[0])
ipinfo['Tor'] = True
except dns.resolver.NXDOMAIN as e:
# Not one
ipinfo['Tor'] = False
except:
ipinfo['Tor'] = 'Check Failed'
Collected information is then saved into a receipt file, the filename of which is derived from the IP of the bot, by replacing periods and colons with hyphens (for example, 129.105.31.75 becomes 129-105-31-75).
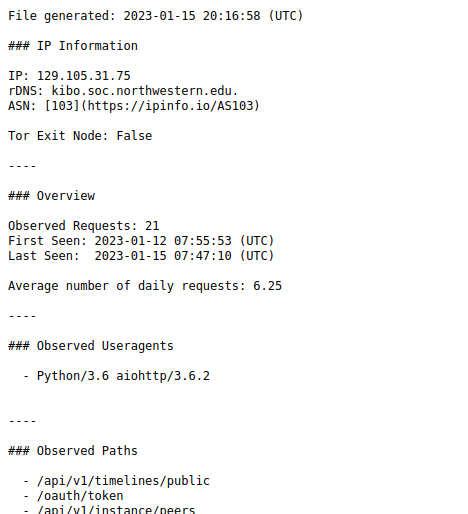
The file above can be seen here and relates to the research bot that I wrote about recently.
I made a conscious decision not to include whois fields which might contain personal or contact information (see Lawful Basis below for more of my thoughts on data-minimisation).
Plain text files are used in order to help ensure that a particularly malicious bot can't include HTML/Javascript in things like it's user-agent in order to try and mess with the receipt files.
Tooting
With the receipt file written to disk, the bot just needs to toot out a report. There's nothing particularly innovative here, it does exactly the same thing as my RSS to Mastodon Bot.
Details are taken from the report, escaping things like periods (again, we don't want a malicious bot injecting stuff into our toot) and a report toot is sent:
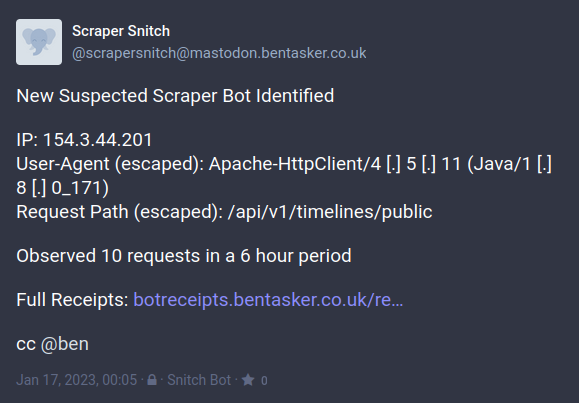
No tags are currently included, because I was concerned about the impact that over-circulation might have, especially if (or, pragmatically, when) a mistake gets made. I don't want the toots to simply appear under #fediblock, with all the trouble that that can bring with it.
As a protection, the use of "Followers Only" isn't perfect: the status is Mastodon specific and not an ActivityPub thing, so if the account is followed by users on a non-Mastodon instance the toot might appear in that instance's federated timeline. Not ideal, but also probably not the end of the world.
Other
Bot Metrics
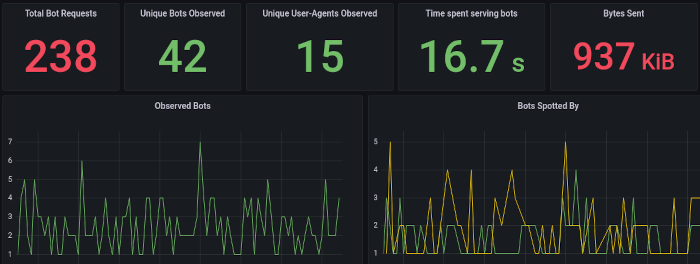
I've built a range of Grafana dashboards aimed at monitoring and troubleshooting the system's operation.
There's a dashboard providing statistics about the data being output by the log agent:
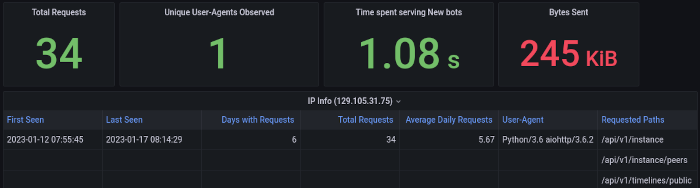
Another allowing drill-down into the behaviour of a specific IP
And a third running different variations of the main analysis query in order to display
- Bots that the query identifies (i.e. those that would be tooted)
- Bots that would otherwise be identified, but fall below the scoring threshold
- Bots that would otherwise be identified, but haven't appeared on enough days
- Bots that would otherwise be identified, but haven't made enough requests in the query period
Each of which provide information to help refine the thresholds used in that final analysis step.
Correcting Mistakes
The design works quite hard to minimise the likelihood of false positives, but it's not impossible that - at some point - a mistake will be made.
In the event that that happens, please either
- Contact Me, and/or
- Reply to the relevant toot (the bot CC's my main account)
Please be aware, that if you're claiming that an IP is yours and has been miscategorised, you will need to be able to prove control of that IP (usually, by making an arbitrary web-request that I'll provide you with).
Lawful Basis
It would be remiss of me not to also lay out the lawful basis for the collection and processing of this data.
The Privacy Policy on mastodon.bentasker.co.uk discloses that this processing may occur, along with the (potentially) personal information which is collected:
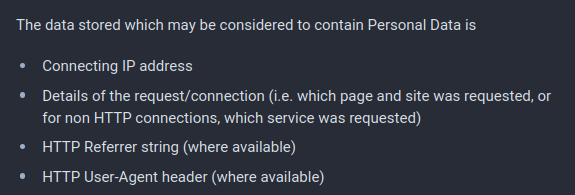
If it seems overly cautious to have included HTTP headers in the list, you'll be surprised to learn that some bot authors do, in fact, include their name in the user-agent header.
Edit: The following is incorrect, and retained only for reference. See below for the up to date position.
I do not consider that my processing is subject to GDPR, because it falls under the "Domestic Purposes" exemption.
The implementation was built in my free time because I care about privacy and safety, there is no connection to either a professional or commercial activity, I do not charge for the information and I do not intend to.
Although I believe that the processing is not subject to GDPR, I do intend to continue to adhere to core principles such as that of data minimisation:
- receipts contain only the information *necessary* for other administrators to make an informed decision, and no more
- Minimal information from `whois` is included, to mitigate the risk of accidentally disclosing information relating to the network operator, even if it is taken from a public source.
As detailed above (in Correcting Mistakes), if it's established that an error has occurred, receipts and associated toots will be deleted or corrected as reasonably appropriate. For valid reports/receipts, content will be retained until the last observed activity from that IP was at least 6 months ago.
Of course, if a competent Data Protection Authority wishes to disagree with my assessment, I'm more than happy to hear it and make adjustments (please Contact Me).
It's been pointed out to me that the above is incorrect: the domestic exemption cannot be relied upon when disclosing information to others (which makes sense, now that I think about it).
So, I've done some work revisiting this and concluded that the processing should rely upon the lawful basis of Legitimate Interest.
As required, I have now completed a Legitimate Interest Assessment (LIA) seeking to balance the impact on data subjects with the processing need.
I'm not going to publish the full LIA, but to summarise:
- Recital 49 to the UK GDPR permits the processing of personal data necessary for the purposes of network and information security.
- The processing occurs in pursuit of both my own interests as well as the interests of a wider society (the fediverse), and is necessary in order to achieve those aims.
- The processing is proportionate, in that it is a reasonable response to the threat posed by scraping, with minimal (but non-zero) associated harm to a data subject, if the scraper is a private individual.
- The (potentially) personal data disclosed is minimised to that which is necessary
- An individual running a scraper can reasonably expect that administrators will (or at least may) take steps to prevent scraping, including possible disclosure (which is not uncommon in other areas of the industry)
The LIA identified an additional means to mitigate harm caused as the result of a mistake: the bot will also be updated to only publish during UK daytime hours (to help minimise the chances of a mistake being published and remaining public whilst I'm asleep).
My Mastodon Privacy Policy has been updated to reflect these changes.
But It's Public Data
This is something I've occasionally responded to on Mastodon, but haven't written much down about here, so wanted to do so now in order to try and help put this point to bed a bit.
Whenever a debate arises around a new scraper, the same point is inevitably made: "the data is public, so you can't complain about someone scraping it".
Wrong.
There is a significant difference between making something public and consenting to it being taken and made part of an easily searchable collection under the control of somebody else.
Making something public means accepting that there is a risk that this might happen, it does not, however signal consent to that activity.
Searchable indexes of social media activity have, historically, been used to help target and facilitate harassment and abuse campaigns, leading to doxxing, SWATting and attempts to coerce suicide.
Even seemingly "harmless" public instance metadata has been mis-used for these purposes.
There is a tool (which I won't link to) which allows the user to search and see which instances block another instance (and why, if the reason's been published). It was created by Kiwi Farms and is most commonly used to identify instances to target for pile-ons (if you're wondering why some instances no longer publish their block-lists, this is a big part of it).
If the strength of the pushback against a fediverse indexer comes as a surprise to you, it's probably a sign that you've not fully considered the consequences of the implementation. Consequences that many of those in the fediverse have personally had to suffer through.
If your only defence against this is to tell strangers "I'm different, trust me", then you've really not properly understood the issues.
It is true that the data being scraped is made publicly available, but there's a difference between information being spread across an entire fediverse of sources, and it being indexed into an easily searchable compendium.
As an easy non-Mastodon example: if I'm looking to see how widely a vulnerable web application is used, I wouldn't usually run curl against the entire internet, I'd go straight to Shodan and search there. Without that convenience, how often would I actually bother checking and how much would I miss when I did?
This ease of use is what makes indexes so valuable to abusers and so unwelcome to their potential targets.
By definition, any implementation working on an opt-out basis, is operating only on the assumption of consent. If a developer feels that their implementation wouldn't see sufficient uptake using opt-in, it should probably be taken as a warning about what they're intending to do.
As another server admin aptly put it
People have signed up here with an understanding of what this place is and how it works. Dragging them and the things they produce into searches against their wishes and against the wishes of the admins running so much of the place is changing the playing field beneath them. Instead, look at making a new playing field and let people decide if they want to play there under whatever the proposed rules are
Normally, scraping on the assumption of consent would at (at best) be problematic. However, relying on that assumption whilst operating in an arena that has been consistently vocal in their opposition isn't just problematic, it's downright wrong.
I find it particularly frustrating, because in this case acquiring consent isn't even a particularly hard problem to solve. All that's really necessary is to create an ActivityPub instance and have users follow a specific account in order to opt-in. It even simplifies the system's architecture, because indexable content will get sent straight to the index instance, with no spiders required.
I'm far from the only one to have said this (not even the first) and yet crawler based implementations relying on "but it's public" type defences just keep on popping up.
Google and Legal Status
Whilst I'm on my soapbox, I'd also like to address the tendancy of holding Google up as "proof" that this type of crawling and indexing is a legal activity.
Those making this claim significantly underestimate the legal minefield and compliance costs that Google (and other similar businesses) negotitate whilst going about their daily business.
Web vs Fediverse
Before we start talking legal stuff though, the use of the word "Web crawler" is also actually quite important, because there's a fundamental difference between the benefit model of a Web Search engine and that of a Fediverse Search Engine.
Most web authors derive some form of benefit from being indexed by search engines, which help to drive visitor traffic to content, increasing eyeballs on ads, engagement with content, brand recognition etc etc.
So (although I don't fully agree with it) there is the basis of an argument for assuming consent to Web crawling, along with a well-known and standardised means of signalling that you don't wish for your content (or some part of it) to be included.
The same can't really be said of toots.
A toot's author derives little-to-no benefit from additional eyes seeing their toots (only really incurring any consequences) and every damn fedi-search project seems to want to rely on the presence of some new hashtag in user's bios (more than a few of those projects fail to check robots.txt too).
Of course, things are complicated a little by the fact that Mastodon also makes toots available via the web.
But it doesn't seem unreasonable to expect that this not overly change the way that content is treated by projects that specifically target the fediverse. In fact, if anything, it probably puts the onus even further onto those scrapers to check for noindex and robots.txt rather than assuming consent based on the lack of some newly contrived hashtag.
To summarise, likening the behaviour of fediverse search engines to that of web search engines isn't particularly instructive, because the benefits (and drawbacks) of being indexed are very different on the web.
As a fun aside, the first Web search engine (depending on your definition) - Aliweb - didn't actually use crawlers at all.
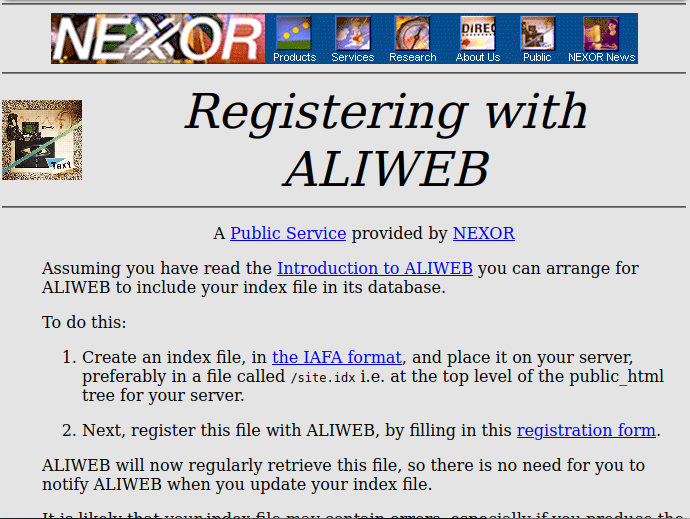
Aliweb relied on site administrators submitting an index file to it. There was no need to assume consent, because authors actively asked to be included. The second search engine (JumpStation) broke this model.
If you want to learn more about Aliweb, it's pages are in the Wayback machine.
The Legal Landscape
Getting back to claims of legality: The short-form answer is that the legal status of scraping is not a simple area of law and anyone who says "Google do it, so this is fine" is wrong.
Even in the US, with it's relatively broad fair-use copyright exemptions, the legal landscape (and a scraper's exposure) varies widely.
Many sources recommend that each scraped site's TOS be checked to ensure it doesn't prohibit the intended behaviour. For more information on the various considerations that need to be made in the US, there's an excellent post written by an entirely different Ben.
Things are also fairly complex in the EU, Ryanair Ltd v PR Aviation BV (2015) found that Ryanair's database of flight times was not protected by Database rights, because it lacked creative input. However the court also made it clear that it is possible for a website's terms and conditions to restrict re-use of mined/scraped data.
In NLA v Meltwater (2015) it was found that unauthorised use of scraped news headlines amounted to Copyright Infringement because creating a headline requires sufficient creative input.
Therefore, to assess the legal status of scraping toots under copyright law, you would need to consider
- How much creative input reasonably goes into a toot: does it cross the threshold?
- How much of the toot is being reproduced (normally, all of it)
- Does the instances TOS prohibit your intended use?
I'd suggest that there's a persuasive argument that many toots do require sufficient creative input and therefore would benefit from Copyright Protection.
Even if we accept that only some toots are able to meet this threshold, in order to avoid liability, the onus would be on the developer to have their scraper correctly identify and exclude these (itself an extremely challenging task that's unlikely to be possible without an unacceptably wide error margin).
The next question to consider is: does this use of a toot constitute possible infringement?
Some may wish to argue that indexing (in the Lucene sense) does not create a copy, or a derivative work and therefore would not constitute a breach of copyright. It's possible that they're right, however, test cases do have a habit of being quite expensive and relying solely on novel defences is generally recommended against (unless you're a particular fan of paying legal fees).
Once the copyright minefield has somehow been navigated, it's then necessary to consider whether a scraper may collect and process anything that could be considered PII (and so fall under GDPR, CPRA or similar), especially if the project will have any kind of a commercial model.
TL-DR: anyone who tells you that crawling is fine "because Google does it" is giving bad advice. The correct advice is: before proceeding, engage and consult with a good technical lawyer who specialises in this area.
Mastodon's Controls
I've said it before and will almost certainly say it again: Mastodon doesn't provide instance administrators with enough insight and say around access control.
Even the controls that do exist sometimes behave in quite suprising ways. For example, whilst looking at justmytoots.com earlier this week, I thought I found that AUTHORIZED_FETCH only protects the toots/profiles of non-admin users - additional testing shows that I was wrong.
The documentation says the following
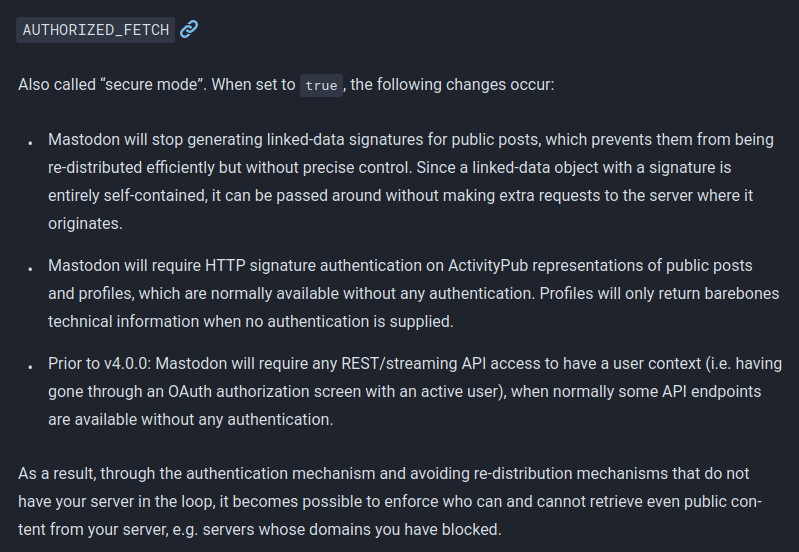
justmytoots.com was fetching profiles via Mastodon's REST API and AUTHORIZED_FETCH does not apply to those endpoints - unfortunately, I think I made a mistake in follow-up testing which led me to an incorrect conclusion.
However, the situation can be clarified as follows
-
AUTHORIZED_FETCHprotects endpoints serving ActivityPub representations (e.g./users/admin/statuses/109783620003703439) but not the REST apis (e.g./api/v1/statuses/109783620003703439) -
DISALLOW_UNAUTHENTICATED_API_ACCESSprotects the REST APIs, but not the ActivityPub representations - Unticking
Allow unauthenticated access to public timelinesprotects neither (but does protect other stuff)
Because each covers different parts of the system, you may find that you want all three enabled (depending on your needs).
Of the three, only DISALLOW_UNAUTHENTICATED_API_ACCESS protects the endpoint that justmytoots.com was using.
justmytoots.com also helped to highlight that Mastodon also uses extremely permissive CORS headers:
curl -v \
-o /dev/null \
-X OPTIONS \
-H 'Origin: https://im.not.real.example' \
-H 'Access-Control-Request-Method: GET' \
https://mastodon.bentasker.co.uk/api/v1/instance 2>&1 | grep access-control
> access-control-request-method: GET
< access-control-allow-origin: *
< access-control-allow-methods: POST, PUT, DELETE, GET, PATCH, OPTIONS
< access-control-expose-headers: Link, X-RateLimit-Reset, X-RateLimit-Limit, X-RateLimit-Remaining, X-Request-Id
< access-control-max-age: 7200
Use of access-control-allow-origin: * means that any website can embed javascript which calls the API on any mastodon instance. Mastodon doesn't appear to provide a way for instance administrators to change this, so the only option is to place a HTTP server like nginx in front and override the header.
Although overriding these headers won't impact apps or users of the Mastodon web-UI, it will impact third party web-UIs like Elk, Pinafore and Semaphore.
Conclusion
This new bot is not a silver bullet, nor is it really intended to be.
Hopefully, though, it'll serve to provide an additional source of information for instance administrators looking to help keep their users safe from harassment.
Whatever your feelings on any of the recent individual fedi-search attempts, the truth is that various potential threats are already quietly attempting to index the fedi-verse. Some of the names involved will almost certainly be familiar to seasoned administrators and can fairly be described as people you really don't want your toots coming to the attention of.
When writing public posts, there's an inherent risk that others may copy, index or mirror that information. However, the existence of that risk does not obviate the need for consent when building a project reliant on consuming information generated by others.
The concept of conditional consent is fairly well established in other areas of our lives, but for some reason continues to be a bone of contention where fediverse scrapers are concerned.
The status of scrapers is a complex area of law, anyone simply pointing to Google as "proof" that their activity is legal would be well advised to seek good legal counsel to ensure they have a full understanding of the obstacles and the liability that may arise when someone objects to their activities.
On its own, IP Blocking doesn't give sufficient protection and so, where possible, should be combined with other techniques. It is, however, better than nothing and can be quite effective against the subset of scrapers who always visit from the same IP.
Within the data-set generated by my log-agent, there are clear indications that some scrapers are attempting to circumvent IP based blocklists using a range of different techniques. Data about these scrapers is not published into botreceipts, because it's difficult to automatically differentiate (at least, with any degree of certainty) between those and mistaken requests by legitimate users. I may, however, write something about some of those bots in future.
At some point, I may find that, in order to evade detection, scraper authors start excluding my instance from their crawls, but it is something that has already been planned for.
Finally, I've written about Mastodon quite a lot recently and I am conscious that because so much focuses on the protections that it offers (or lacks), my tone hasn't always been that positive. To be clear, although it might sometimes read that way, it's really not my intention to shit on Mastodon: just as there are things that it could be doing better, there are things it currently does very well (and honestly, if I didn't like it, I wouldn't be using it).