Allowing your internal search engine to index Gitlab Issues, Commits and Wiki pages
I've basically lived my life inside issue tracking systems - it used to be JIRA, and I had built tooling allowing effective indexing/mirroring of JIRA issues, but then Atlassian decided to all but do away with on-prem users. So, like many others, I moved over to Gitlab instead.
As a product, Gitlab's great: it's got project lifecycle management, issue tracking, wiki support and even a container registry baked straight into it.
However, it's indexability is basically non existent - even if you have projects marked as public, significant parts of pages are fetched by javascript, so a crawler can't index things like issue references (no, I'm not kidding) unless they execute javascript. It's like they reverse search engine optimised...
It's not just on-prem Gitlab either, it also affects their cloud offering.
Search within Gitlab is excellent, but this is of little use if you have things spread across systems and want to search from a single central point (to be fair to Gitlab, their idea is that everything you do should be within their solution, but life rarely actually works that way).
This documentation details how to use my new tooling (rudimentary as it currently is) to expose an indexable version of your Gitlab life. Although this is focused on an on-prem install, this tool should work with their cloud offering too, as the APIs are the same (but I haven't tested against it).
The Issue
It probably makes sense to start by explaining exactly what the issue is.
When you visit a Gitlab issue page like the one at https://gitlab.com/gitlab-examples/security/simply-simple-notes/-/issues/25 you'll see quite a bit of information

There are quite a few pertinent bits of information there that you'd hope to be able to search for:
- in the bottom right, is (IMO) the most important - the issue reference:
gitlab-examples/security/simply-simple-notes#25. - things like the issue title:
Kubernetes cluster unreachable - Labels
- Maybe even the user's names, or the Milestone name.
But, taking that all-important reference as an example, if we check the HTML, it simply doesn't exist
$ curl -s https://gitlab.com/gitlab-examples/security/simply-simple-notes/-/issues/25 | grep "gitlab-examples/security/simply-simple-notes#25" | wc -l 0
In fact, if we get my search bot to dump out what it sees on the page, we can see just how bare it is in terms of usable information
{
"content_hash": "7790c99e424721aae867a9143c5924d4232d728a77bafa3f3d515c6251de841e",
"http": {
"finalurl": {
"domain": "gitlab.com",
"path": "/gitlab-examples/security/simply-simple-notes/-/issues/25",
"querystring": "",
"scheme": "https",
"url": "https://gitlab.com/gitlab-examples/security/simply-simple-notes/-/issues/25"
},
"hasredirect": false,
"headers": {
"Content-Length": null,
"Content-Type": "text/html; charset=utf-8",
"ETag": "W/\"d0e54e0336aeaba5881165a218f74f43\"",
"Last-Modified": null
},
"status": 200
},
"microdata": {
"keywords": [],
"relatedLinks": []
},
"namedanchors": [],
"opengraph": {
"articletags": [],
"pagedescription": "The deploy stage is currently failing with the following error message: Error: Kubernetes cluster unreachable: Get https://34.67.226.137/version?timeout=32s: x509: certificate signed by unknown authority",
"pageimage": "https://gitlab.com/uploads/-/system/project/avatar/15310444/kelly-sikkema-sDqT3iD6vSc-unsplash.jpg",
"pagesite_name": "GitLab",
"pagetitle": "Kubernetes cluster unreachable (#25) \u00b7 Issues \u00b7 GitLab-examples / security / simply-simple-notes",
"pagetype": "object",
"pageurl": "https://gitlab.com/gitlab-examples/security/simply-simple-notes/-/issues/25"
},
"outgoinglinks": {
// truncated for brevity
},
"pagedescription": "The deploy stage is currently failing with the following error message: Error: Kubernetes cluster unreachable: Get https://34.67.226.137/version?timeout=32s: x509: certificate signed by unknown authority",
"pagekeywords": false,
"pagetitle": "Kubernetes cluster unreachable (#25) \u00b7 Issues \u00b7 GitLab-examples / security / simply-simple-notes \u00b7 GitLab",
"reqinfo": {
"domain": "gitlab.com",
"path": "/gitlab-examples/security/simply-simple-notes/-/issues/25",
"querystring": "",
"scheme": "https",
"url": "https://gitlab.com/gitlab-examples/security/simply-simple-notes/-/issues/25"
},
"skipped": false,
"stripped_text": "The is currently failing with the following error message: \n
Error: Kubernetes cluster unreachable: Get https://34.67.226.137/
version?timeout=32s: x509: certificate signed by unknown authority \n",
"urltype": "page"
}
Once the HTML tags are stripped from the page, there's very little there, basically just the issue description
"stripped_text": "The is currently failing with the following error message: \nError: Kubernetes cluster unreachable: Get https://34.67.226.137/version?timeout=32s: x509: certificate signed by unknown authority \n",
None of the following are available in the base HTML, because they're fetched with javascript
- Issue reference
- Comments
- Labels (or indeed anything in that right sidebar)
- State changes (including commit mentions)
So, your chances of finding an issue by searching essentially depends on whether you know the title or enough of the text in the description.
That's.... not great for discoverabilty.
My Solution
Quite some time back, I addressed a similar need with JIRA (in that case it was the auth flow that stood in my way, indexability was actually otherwise not too bad) by creating my Jira-Issue-Listing Script (JILS).
Although you could, perhaps, hack at Gitlab's template to rectify issues, the advantage of running a JILS-like solution is it also makes it trivial to store a usable backup of your project management - if Gitlab should go bang tomorrow, you still have HTML archives to refer back to.
The JILS code is ooold, and was never that great anyway, so rather than forking it, I essentially just borrowed the templating elements to get a nice minimalistic interface that's tilted towards optimal indexing
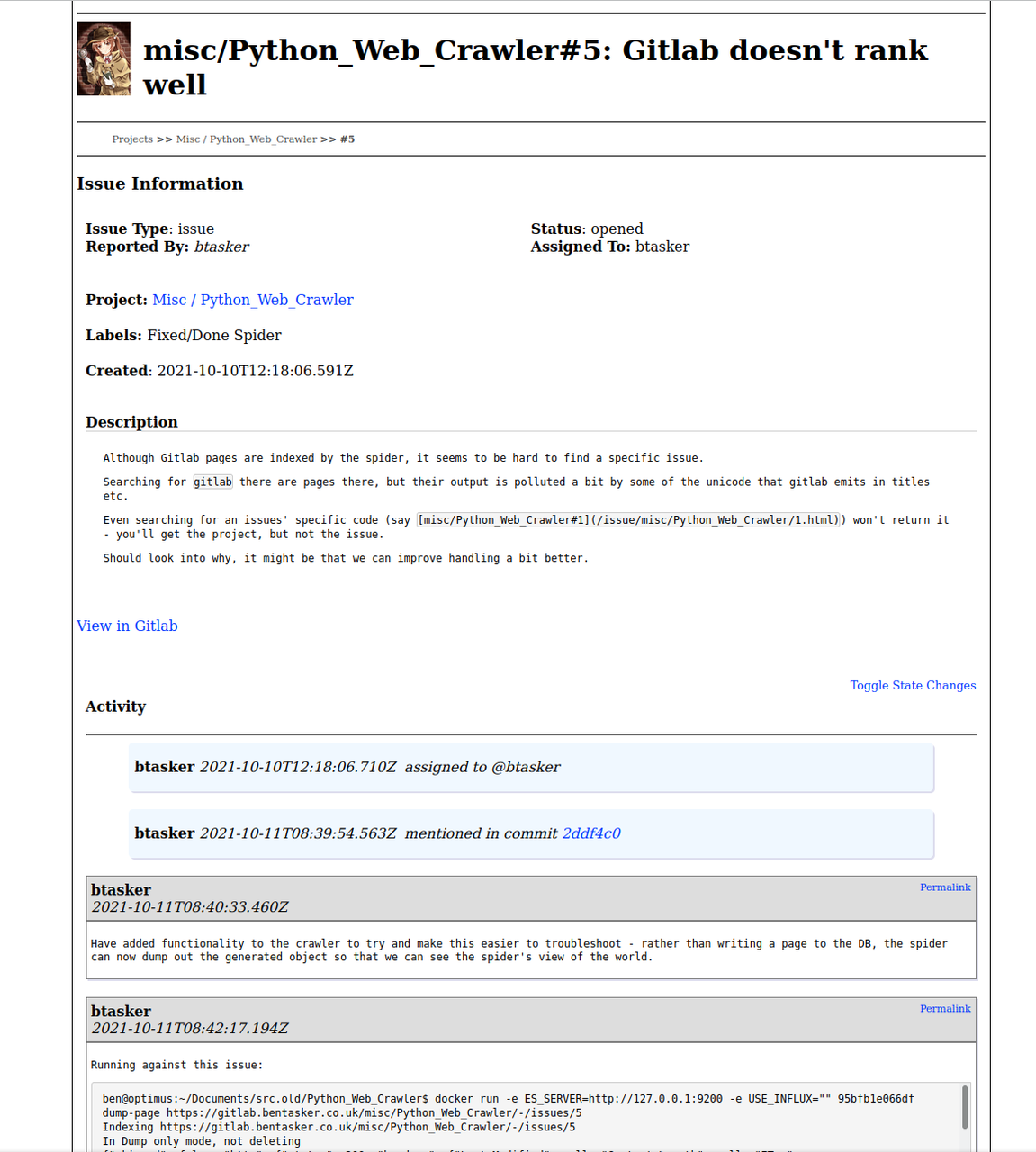
If we compare the indexable text between this page and it's Gitlab counterpart, it's night and day:
Before
{
"pagedescription": "Although Gitlab pages are indexed by the spider, it seems to be hard to find a specific issue. Searching for gitlab there are pages there, but...",
"pagekeywords": false,
"pagetitle": "Gitlab doesn't rank well (#5) \u00b7 Issues \u00b7 Misc / Python_Web_Crawler \u00b7 GitLab",
"reqinfo": {
"domain": "gitlabinternal.bentasker.co.uk",
"path": "/misc/Python_Web_Crawler/-/issues/5",
"querystring": "",
"scheme": "https",
"url": "https://gitlabinternal.bentasker.co.uk/misc/Python_Web_Crawler/-/issues/5"
},
"skipped": false,
"stripped_text": "Although Gitlab pages are indexed by the spider, it seems to be hard to find a specific issue. \n
Searching for gitlab there are pages there, but their output is polluted a bit by some of the unicode that gitlab
emits in titles etc. \nEven searching for an issues' specific code (say misc/Python_Web_Crawler#1 ) won't return it
- you'll get the project, but not the issue. \nShould look into why, it might be that we can improve handling a bit
better. \n",
"urltype": "page"
}
After
{
"pagedescription": "misc/Python_Web_Crawler#5 Although Gitlab pages are indexed by the spider, it seems to be hard to find a specific issue.\n\n
Searching for `gitlab` there are pages there, but their output is polluted a bit by some of the unicode that gitlab emits in titles etc.\n\n
Even searching for an issues' specific code (say `[misc/Python_Web_Crawler#1](/issue/misc/Python_Web_Crawler/1.html)`) won't return it -
you'll get the project, but not the issue.\n\nShould look into why, it might be that we can improve handling a bit better.",
"pagekeywords": false,
"pagetitle": "misc/Python_Web_Crawler#5 : Gitlab doesn't rank well",
"reqinfo": {
"domain": "gilsdemo.bentasker.co.uk",
"path": "/issue/misc/Python_Web_Crawler/5.html",
"querystring": "",
"scheme": "https",
"url": "https://gilsdemo.bentasker.co.uk/issue/misc/Python_Web_Crawler/5.html"
},
"skipped": false,
"stripped_text": "Although Gitlab pages are indexed by the spider, it seems to be hard to find a specific issue. \n
Searching for gitlab there are pages there, but their output is polluted a bit by some of the unicode that gitlab emits in titles etc. \n
Even searching for an issues' specific code (say [misc/Python_Web_Crawler#1](/issue/misc/Python_Web_Crawler/1.html) )
won't return it - you'll get the project, but not the issue. \n
Should look into why, it might be that we can improve handling a bit better. \n
assigned to @btasker \n
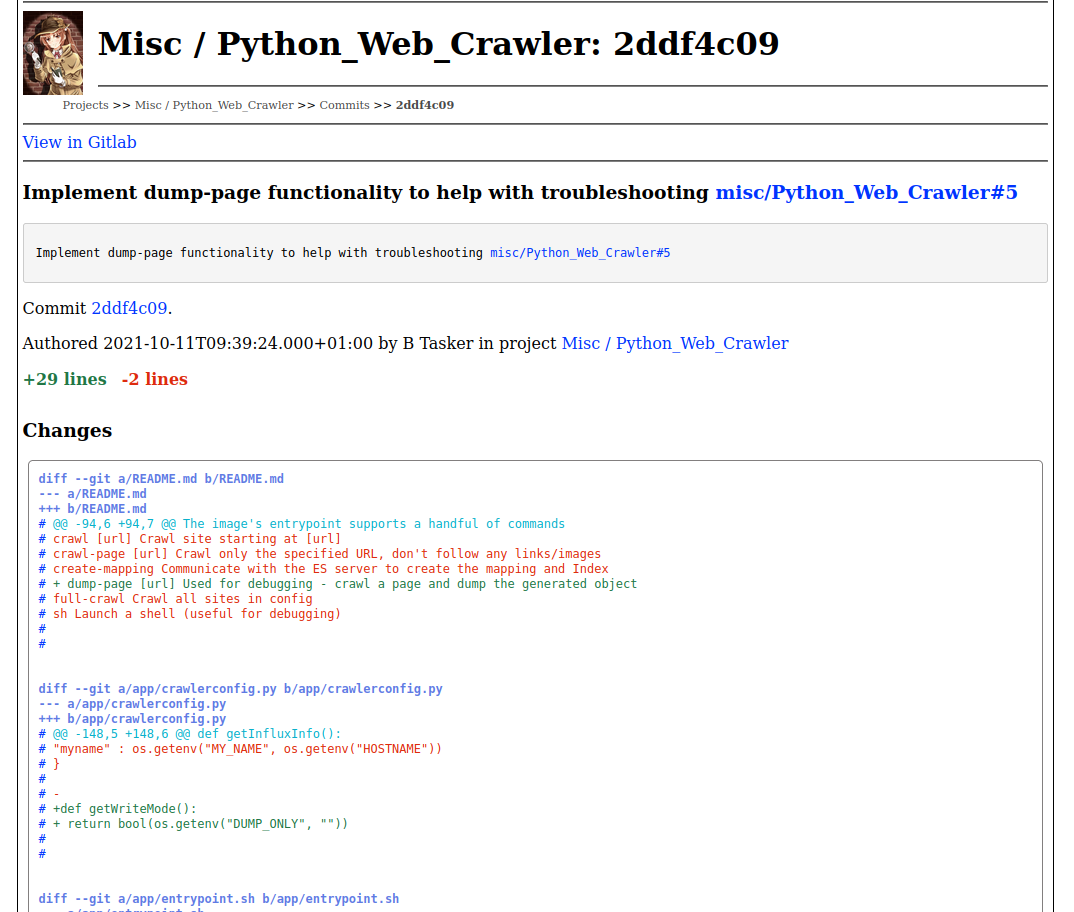
mentioned in commit \n
Have added functionality to the crawler to try and make this easier to troubleshoot - rather than writing a page to the DB,
the spider can now dump out the generated object so that we can see the spider's view of the world. \n
Running against this issue: \n
Which gives us \n
Of that object, there are a few things that stand out: \n
This is the text of the issue description.
No comments are included though. \n
Checking with curl it's because they're not in the base page \n
Nor is the issue reference \n
.... I trucated for brevity, you get the idea ...
",
"urltype": "page"
}
As well as a full set of text to index, you'll notice the the meta description is much more verbose, the title is more succinct
The page is also laced with things that my bot can consume, like schema.org markup.
Unlike in JILS, we're also able to show commit information
And, just like with it's predecessor, GILS allows you to take a backup as simply as running
wget -R "robots.txt" -r -p -k "[url to GILS]"
My search bot (based on the one I described here) happily chomps through the pages
Supported Views
The following views/sections are currently supported
- Project listing
- Project Issues
- Commits
- Wiki Pages
- Container registry
- Images/avatars etc
Essentially, it's currently tailored around the bits of Gitlab I use and considered a priority for indexing. The eventual aim is that each view will be config gated so that you can avoid indexing areas you don't care about searching for.
Running It - Prep
There's just a little bit of setup required ahead of time, some of this is required due to oddities in Gitlab's authentication structure.
You'll need to
- Create a user to authenticate as
- Impersonate that user and create a personal access token - it'll need the API read privilege.
You'll need to do this even if you only intend to mirror public projects. For some reason, the notes api end point (the one used to fetch comments and state changes) will not accept unauthenticated calls.
GILS includes a configuration option ($public_projects_only) that allows you to drop privileges to generate the initial project list (so that only public projects are included), however it's not perfect and internal projects may get included if they're linked to from a public project (it's on the list for the next release).
Running It
GILS is released as a docker image, all you need to do before running it is create a configuration file
<?php
class GILSConfig {
public $server = "https://mygitlab.com"; # Replace this
public $access_token = "yourtoken"; # Generate a token with API read privs
/* Replace http:// with https:// in URLs returned by the Gitlab API
You may see this if your gitlab instance is talking HTTP but access via a
HTTPS reverse proxy.
This setting should only be used temporarily, if the above is the case then
things like attaching images to wiki pages is probably also broken.
See
https://forum.gitlab.com/t/wiki-file-attached-issue-server-responded-with-0-code/31862
*/
public $force_https = false;
/* If this is true, only projects that are
marked as public will be listed on the project list page.
However (currently) if a non-public issue is linked to from another project
it'll be accessible from that route. This will be fixed in a later release
*/
public $public_projects_only = true;
}
Amend as appropriate and then save this somewhere.
Pull and run the image from my docker repo:
docker run -d --name=GILS -h GILS \
-v $PWD/config.php:/var/www/html/config/config.php -p 80:80 \
--restart=always \
bentasker12/gitlab-issue-listing-script:0.2.3
Amend the path to config.php if it's not in your current working directory.
This will stand up an instance bound to port 80, and you should be able to hit it immediately.
Once you're happy, it's just a case of pointing your search engine spider at it.
Notes/Advantages
There are a number of additional advantages to using GILS.
It's very light-weight, and particularly with the addition of a caching layer (either Redis or Memcached support will be added in future), allows for significant scaling of read-centric traffic. You can have a bunch of read-only viewers hit GILS pages without needing to worry too much about Gitlab's RAM noshing ways. Each page links out to it's Gitlab equivalent, so users that do need to complete actions can trivially do so.
Almost more importantly that being able to index your issues though, is being able to index your wiki pages.
As bad as it might be not to be able to search for project issues, the idea of a wiki not being trivially indexable is a million times worse, compounded only by the possibility of a user finding a wiki page, but not being able to view it because of Javascript issues.
Future Plans
There are a few bits currently on the "definitely want to implement" list:
- Add support for the "Issue relations" section in the Issue view
- Support for Milestones and releases within projects
- Allow the conditional export of specific projects, allowing creation of a public-only mirror, not dissimilar to the one I used to maintain for my JIRA projects.
- Config gating of all supported views - don't want to index commits? Turn those views off
- Finish the "public projects only" implementation to prevent accidental leakage
- Implement support for either Redis or memcached so pages can load without the traditional Gitlab lag
- As the system is driven by API calls, it should be possible to make that section pluggable so that the system can instead be backed by Github (to allow indexing/backup of private repos)
For now, though, I'm just happy that my search engine can now actually find things that are in Gitlab.