The Pitfalls of Building an Elasticsearch backed Search Engine
There are a ton of articles on the internet describing how to go about building a self-hosted fulltext search engine using ElasticSearch.
Most of the tutorials I read describe a fairly simple process, install some software, write a little bit of code to insert and extract data.
The underlying principle really is:
- Install and set up ElasticSearch
- Create a spider/crawler or otherwise insert your content into Elasticsearch
- Create a simple web interface to submit searches to Elasticsearch
- ???
- Profit
At the end of it you get a working search engine. The problem is, that search engine is crap.
It's not that it can't be saved (it definitely can), so much as that most tutorials seem not to lend any thought to improving the quality of search results - it returns some results and that's good enough.
Over the years, I've built up a lot of internal notes, JIRA tickets etc, so for years I ran a self-hosted internal search engine based upon Sphider. It's code quality is somewhat questionable, and it's not been updated in years, but it sat there and it worked.
The time came to replace it, and experiments with off-the-shelf things like yaCy didn't go as well as hoped, so I hit the point where I considered self-implementing. Enter ElasticSearch, and enter the aforementioned Internet tutorials.
The intention of this post isn't to detail the process I followed, but really to document some of the issues I hit that don't seem (to me) to be too well served by the main body of existing tutorials on the net.
The title of each section is a clicky link back to itself.
Overview
I first toyed with the idea of replacing Sphider a couple of years back, and had actually already created a spider in Python which could pull pages, index them and extract outgoing links (as well as things like schema.org markup). So, the plan was to reuse this code to hopefully throw together a proof of concept quite quickly - this is a choice I came to regret a little bit.
The implementation was built on a NFS booted Raspberry Pi. The reason for this is that my earlier experimentation with yaCy had been run on the same Pi, and Solr performed alright there, so I figured being able to compare the two might be helpful. An attached USB thumb-drive is used for ElasticSearch's data directory (as it was for Solr) in order to ensure NFS performance doesn't impact indexing and searches.
Once the teething troubles mentioned here were overcome, it actually started to perform quite well - to the extent that I've now gone to the effort of extending the crawler so that images are also indexed, giving functionality that Sphider was missing
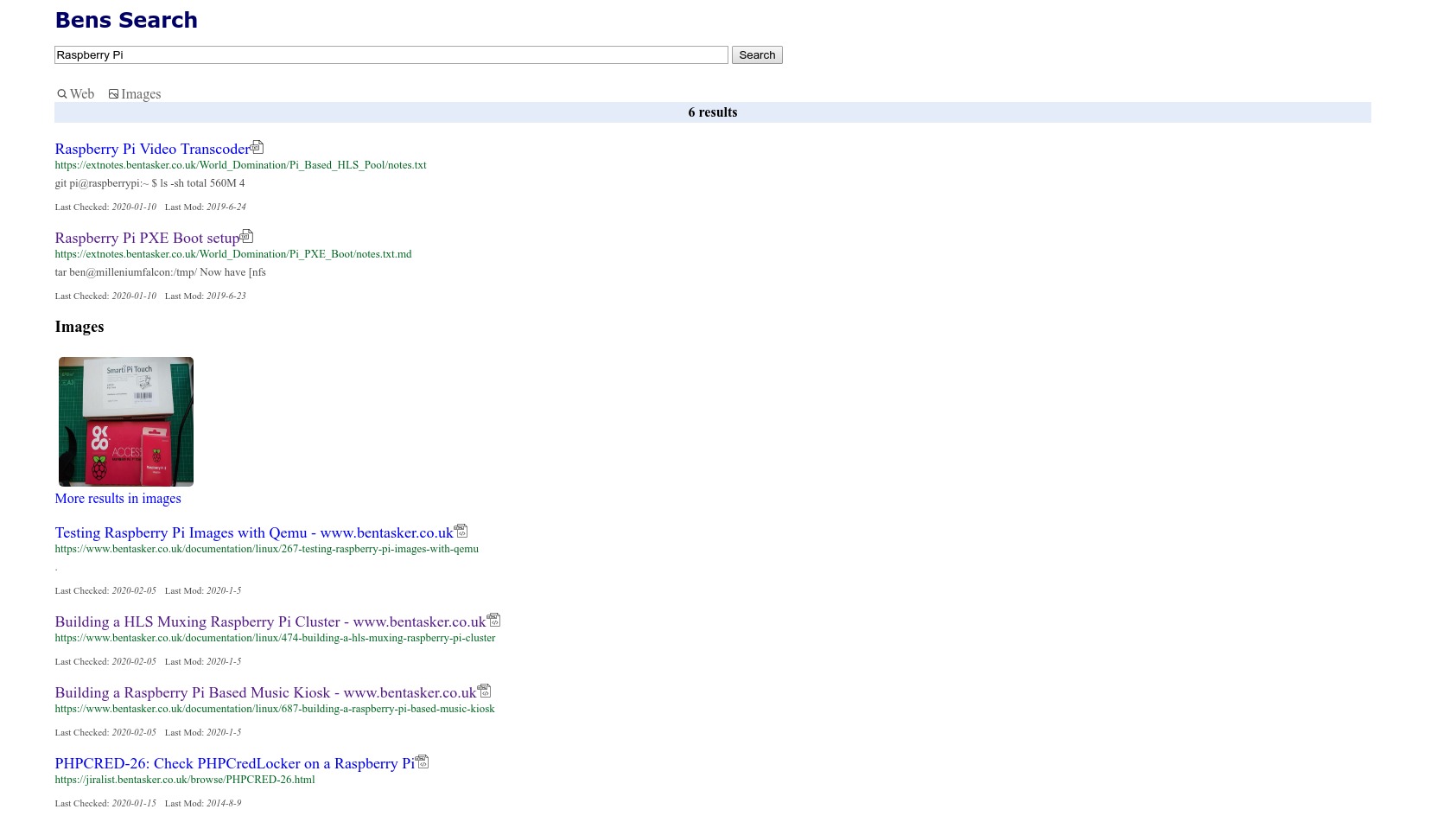
Setup
Ultimately the system consists of
- Nginx
- ElasticSearch
- Python Crawler Script
- Static HTML and Javascript for Search Portal
Self-Inflicted - Python 2
Let's start with one that was entirely self-inflicted.
In order to "move fast", I decided to re-use some code I'd written previously. It's quite a nice little crawler really as it can pull out semantic/structured markup.
But, it was written using Python 2 (now officially an unsupported language). As clever as the semantic data processing might be, I've not actually used the data it generates in the indexes, and the codebase needed various tweaks and improvements over time.
The result being that I've got a nice, working, solution but it's written in a defunct language and is going to need porting over to Python 3 at some point in the near future. I was aware of this when I started, but worked on the basis that the crawler was in theory "oven ready".
This is also part of the reason why this post isn't a tutorial on building your own search engine - there really isn't much point/benefit in me detailing how to do it if the code I'm going to be sharing is in Python 2.
Splitting Pages into Sentences/Paragraphs
Various tutorials will recommend chunking page content down to paragraphs or even sentences, and inserting each individually into ElasticSearch. The logic behind this is sound enough - it means that scoring is performed based on smaller chunks, which should hopefully result in more relevant results being returned.
What's not always sound though, is the method of chunking down.
Take the following example
for sentence in page_text.split('.'):
insertIntoIndex(sentence)
On the face of it, this should be fine. It breaks the page text up into sentences and inserts each individually.
However, in practice, this is absolutely not fine. The above will split on a period wherever it occurs, meaning that things like hostnames will be inserted as individual entities. So if your page text is
www.bentasker.co.uk contains lots of stuff.
Searching for www.bentasker.co.uk will not return a match, because it's been inserted into the index as
- www
- bentasker
- co
- uk
- contains lots of stuff
Not being able to search by hostname is a bit of a showstopper for me, though it's not just limited to those. Searching for h.264 should return (at least) this and this, but won't, because h and 264 are separate entries in the index.
If you are going to split on a period, it's important to do so only if it's followed by a newline or a space
import re
for sentence in re.split('\.($|\ )',page_text):
insertIntoIndex(sentence)
(Just as a side note, you also want to batch insert for performance reasons - it's just easier not to in psuedo-code).
Use HTTP Keep-Alive Connections
When building your spider, you absolutely should make use of keep-alive pools. Far too many tutorials will do something like this
import requests
def fetchPage(url):
''' Example, so yeah there's no error handling
'''
r = requests.get(url)
return r.content
def main():
content=fetchPage("https://www.bentasker.co.uk")
// then do something...
This works, but for each and every page you fetch you're going to establish a new TCP connection to the hosting server. Not only does this slow your crawl, but it puts undue strain on the origin server too.
Instead, you should make use of a keep-alive pool. Python's requests has one that's trivial to use.
def fetchPage(url,reqpool):
''' Example, so yeah there's no error handling
'''
r = reqpool.get(url)
return r.content
def main():
reqpool = requests.Session()
content=fetchPage("https://www.bentasker.co.uk")
// then do something...
If the same instance of requests.Session is passed in each time, any existing connections to the origin in that pool will be reused rather than establishing a new one. You could (but shouldn't) make it a global to reduce the need to pass it around (better to design so it doesn't need to be passed around too much). Spoiler alert: I was lazy and made it a global.
Store the Indexing Date
Any search engine worth it's salt will periodically check that items it's indexed are still valid. This isn't the same thing as a recrawl, because generally a recrawl won't account for pages that no longer exist.
Imagine the index page links to the following
foo.htmlbar.htmlsed.html
Then one day, you edit it to remove the reference to sed.html and delete that file. It's not an awful lot of use to you if your search engine will continue to return links to sed.html (nobody likes a face full of 404).
So, you'll want to periodically recheck that URLs in the index are still valid. Although you should already be storing information useful in revalidation (like Last-Modified), knowing when they were last considered valid is useful in making this more efficient (I also ultimately ended up exposing this info in the search portal itself).
When selecting pages to revalidate, you could choose to order by the oldest, but in order to do this you'll need to update your Elasticsearch mapping and re-index.
I decided instead to choose a random selection of URLs from the index, and then skip any that were indexed/validated today (revalidation runs after the daily crawl completes).
The query to select a random set is pretty straightforward:
def getSet():
''' Get a random set of URLs from the index.
Elasticsearch returns 10 items, which suits us well
'''
global reqs # get the requests keep-alive pool
try:
reqheaders = {"User-agent":MY_USER_AGENT}
# Build the query
payload = {
"query": {
"function_score" : {
"query" : { "match": {
"location": 0 # Get first sentences only
}
},
"random_score" : {}
}
}
}
req = reqs.post("{}/{}/_search".format(ES_SERVER,MY_INDEX),json=payload,headers=reqheaders)
response = req.content
except:
return False
# Decode the JSON
try:
rjson = json.loads(response)
if "hits" in rjson and rjson['hits']['total'] > 0:
return rjson['hits']['hits']
except:
return False
The revalidation script then goes onto check the indexing date before performing Last-Mod/Etag based revalidation of the content on the origin.
Search results are (way) too narrow
Once I thought I had a working implementation, I did a side by side comparison of search results between Elasticsearch and Sphider.
Sphider annihilated ElasticSearch, it wasn't even close.
Elasticsearches results were generally relevant to the search term, but the result set was incredibly limited and very narrowly focused. This meant in once case that Elastisearch returned 2 results, whilst Sphider returned 88 (the search term was Elasticsearch). All of the test-cases resulted in a similar imbalance, and Elasticsearch's results weren't always defensible as the better matches.
What this means is that Elasticsearch was giving very, very little opportunity for discovery and relying heavily on you knowing exactly the right thing to search for. Not particularly helpful in a search engine. In fact, because Elasticsearch performed so badly, I nearly abandoned the experiment - it was only really my curiosity of how it could be underperforming so much that drove me to look further into it.
The root cause of this is in the query passed through to Elasticsearch.
Tutorials will commonly have you build quite a simple query. If it's using the querystring it might even be as simple as
term = document.getElementById('searchterm').value;
url = "/search?term=" + encodeURI(term);
fetchPage(url,writeResults,failedSearch);
Or, equally commonly, use something like simple_query_string in a JSON payload
{
"from": 0,
"size": 100,
"query": {
"simple_query_string" : {
"query": "Elasticsearch",
"fields": ["title", "url","meta_desc","meta_keywords","text"],
}
}
}
The result is working, but extremely narrow search.
What's required is a little bit of fuzziness. This attribute sets the acceptable edit distance between your search term and candidate results. You might also choose to add additional weight to some of the fields, and impose minimum matching requirements, giving you something like this
{
"from": 0,
"size": 1000,
"query":{
"multi_match": {
"query": term,
"fields": ["title^8","url^4","meta_desc","meta_keywords^3","text^3"],
"fuzziness": 3,
"minimum_should_match":"75%"
}
}
}
Whilst this will work, however, it brings with it a new issue
Make Elasticsearch Prefer Exact Matches
You now get a much, much broader result set, but Elasticsearch doesn't order non-fuzzy results first, so your "best" matches are mixed in with everything else.
As an example of the impact of this - there are certain tasks that I do so rarely that I tend to search my notes for the exact syntax for a command (as well as what commands I might run after). Creating a new logical volume in LVM is one of these.
Within my notes I'm looking for a line like
lvcreate -L 100G -n nextcloud VolGroupRaid
Similar lines occur in multiple files, so there should be a reasonable hope of finding it.
So, I search for the term lvcreate. However, with a fuzziness of 3, the word create is considered an acceptable match. Being quite a common word, the result is that I get a lot of pages back, and the ones I actually want are buried within them somewhere.
Clearly, exact matches should be ranked higher. There are requests and references to it on the Elasticsearch forums, but where answers are given they tend to be a fairly vague "use a boolean query". This is the correct answer, just not particularly forthcoming in it's helpfulness.
What you need to do is to create a boolean query which consists of multiple queries with an associated boost, essentially stating that
- A match must contain the term of it's fuzzy equivalents
- A non fuzzy match should have it's score boosted by
n
I went a little further and added 2 additional boosts:
- If all words in the phrase appear in the result, boost
- If we get an exact phrase match, boost even further
The resulting query is constructed as follows
searchobj = {
"from": 0,
"size": 1000,
"query":{
"bool":{
"must" : [
{
"multi_match": {
"query": term,
"fields": ["title^8","url^4","meta_desc","meta_keywords^3","text^3"],
"fuzziness": 3,
"minimum_should_match":"75%"
}
}
],
"should": [
{
"multi_match": { // Non-fuzzy results should be boosted (BSE-11)
"query": term,
"fields": ["title^8","url^4","meta_desc","meta_keywords^3","text^3"],
"minimum_should_match":"75%",
"boost": 6
},
"multi_match": { // Boost if all words in phrase appear (BSE-11)
"query": term,
"fields": ["title^8","url^4","meta_desc","meta_keywords^3","text^3"],
"operator": "and",
"boost": 8
},
"multi_match": { // If we get an exact phrase match, boost that right up (BSE-11)
"query": term,
"fields": ["title^8","url^4","meta_desc","meta_keywords^3","text^3"],
"type": "phrase",
"boost": 10
},
}
],
}
}
}
Now, when I search for lvcreate the very first result is a notes file containing the command. In fact, the first 6 results are notes files containing the command. After those, there are plenty of matches containing the word create but they're no longer obscuring the matches I care about.
Results retain the benefits of fuzziness, whilst promoting the very closest matches within the resultset.
Image Indexing
There are lots and lots of different techniques used for indexing images. Some will pull EXIF data out of JPGs and index that, others use information from where the images are referenced etc.
However, there's one simple bit of advice here that applies whatever the technique - always have your spider generate thumbnails of images it's indexed. Use these in your search results so that a search doesn't end up with your browser trying to pull 200MB of images down.
ElasticSearch Exposure
This should go without saying, but unfortunately doesn't seem to.
Exposing Elasticsearch to networks directly is extremely unwise, even more so the Internet. Where there's a remote need to interact with it, you always want to have some kind of intermediary to limit those interactions a bit.
For your search portal, that means rather than making requests directly to Elasticsearch, you might instead make them against a path that Nginx can proxy through
server {
listen 443;
root /usr/local/searchportal/;
index index.html;
server_name esearch.bentasker.co.uk;
ssl on;
ssl_certificate /etc/ssl/search.crt;
ssl_certificate_key /etc/ssl/search.key;
location /search {
proxy_pass http://127.0.0.1:9200/searchind/_search;
}
location / {
try_files $uri $uri/ =404;
}
}
Whilst this isn't in itself perfect (it's doing nothing to validate/clean payloads), it at least limits submitted operations to the search endpoint.
Even better would be to have searches submitted into some server-side code which processes, translates and then places the request (safely) to Elasticsearch on your behalf.
Conclusion
It's more than possible to build a decent, functional search engine with Elasticsearch. My setup performs well enough, even running on a Raspberry Pi 3B - though I expect at some point I will probably need to migrate Elasticsearch off the Pi in order to improve performance a bit.
It feels, though, as though a lot of tutorials in this area have been written without actually using the resulting stack in anger.
Finding information on some of these issues can be quite challenging. Much like with the default search mechanism, you tend to need to already know the exact terms to search for, and then may need to translate a one sentence reply ("Use a boolean search") into something meaningful.
My implementation continues to develop - adding image indexing was a fairly recent development, so I fully expect that I'll discover new frustrations along the way. But, my confidence in it has grown sufficiently that I've now been able to fully decommission Sphider.
My intention - at some point - is to create a publicly accessible instance allowing search of my various points. Before that can happen though, I'll need to spend some time hardening the setup so that Elasticsearch is less exposed to the net than it'd currently be.